
网安AI筑基篇-生成式AI原理


1.1 LLM原理
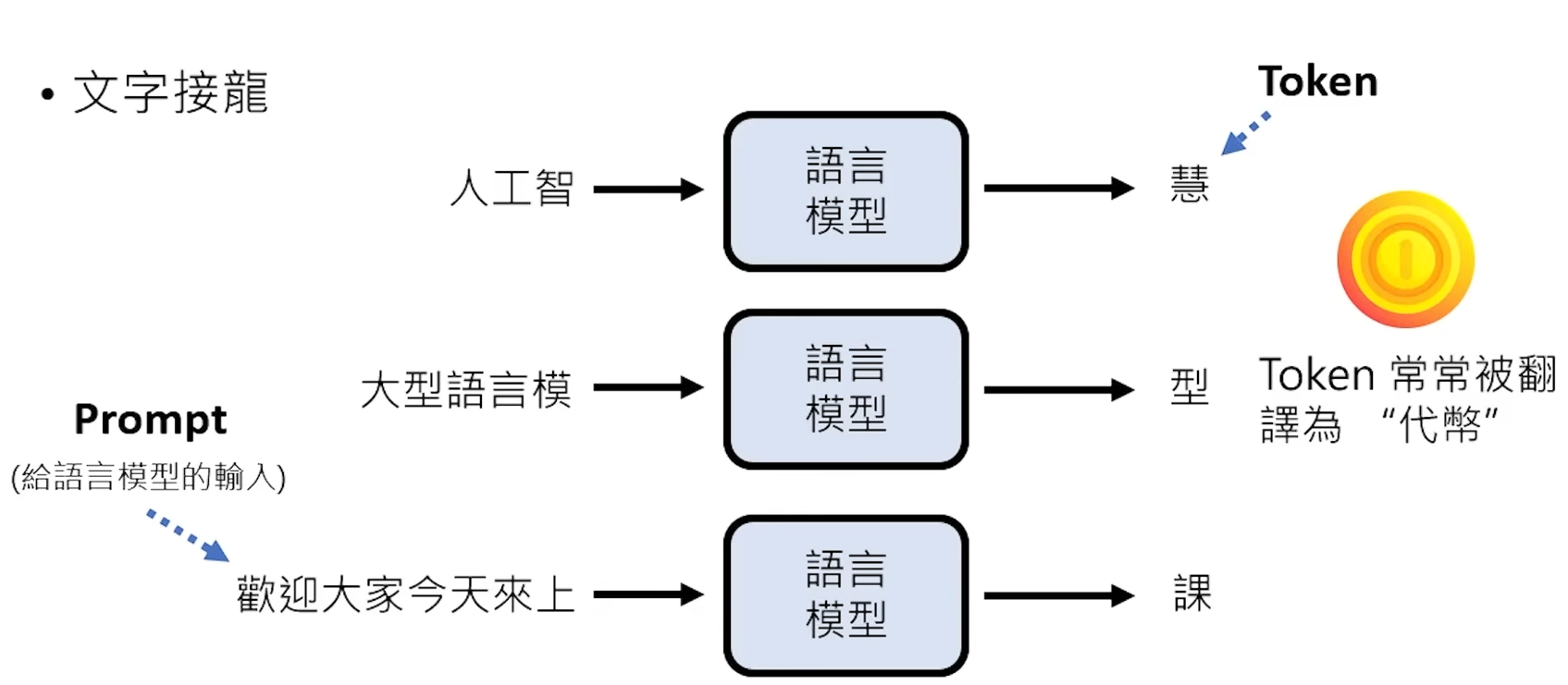
LLM 大语言模型 本质工作是用来进行“文字接龙”,例:用户输入“人工智” LLM进行猜测输出“能”;用户输入内容被称为Prompt ,LLM进行猜测中可以选择的输出被称为Token。
LLM如何回答用户问题?
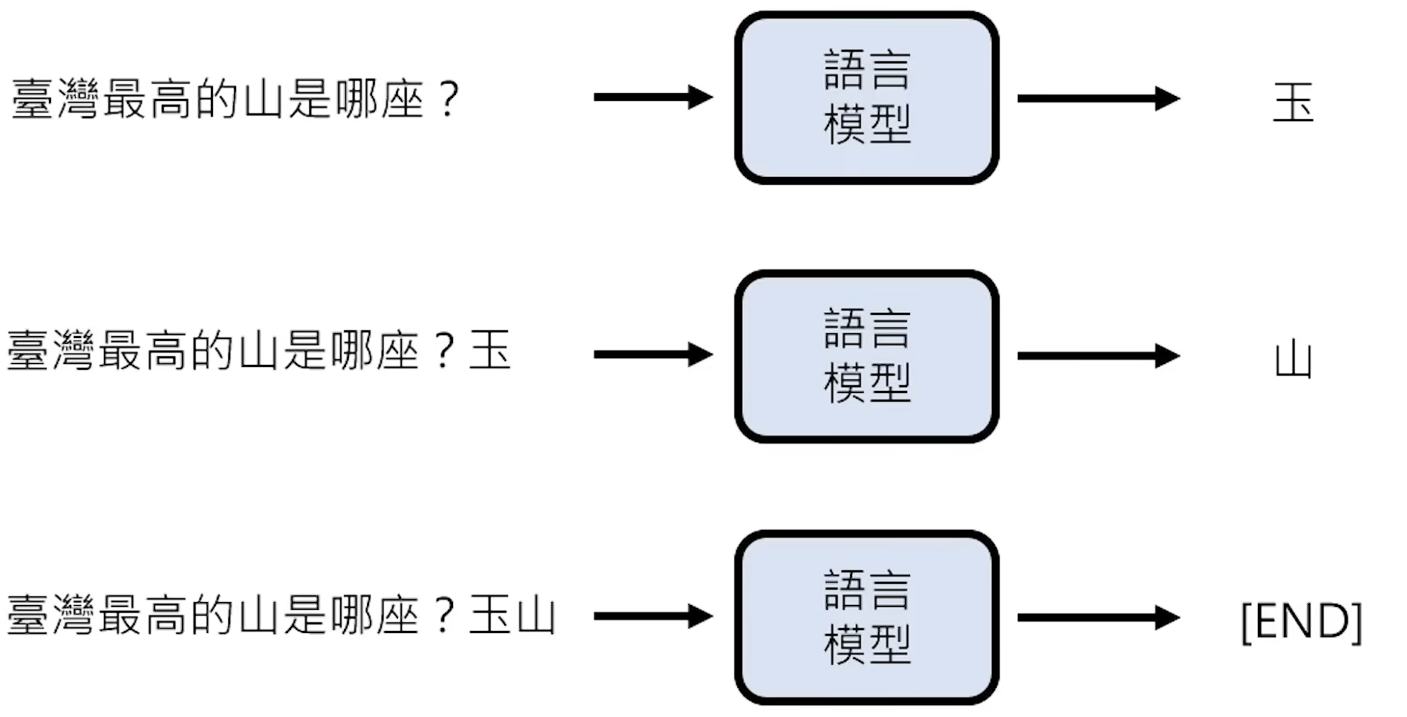
当用户输入一个“Prompt”时,AI会将初始“Prompt”当成一个未完成的句子,进行“文字接龙”消耗Token拼接一个文字之后,当作第二轮的Prompt进行接龙,一直循环往复,直到无Token可以猜测。
Token输出的选择
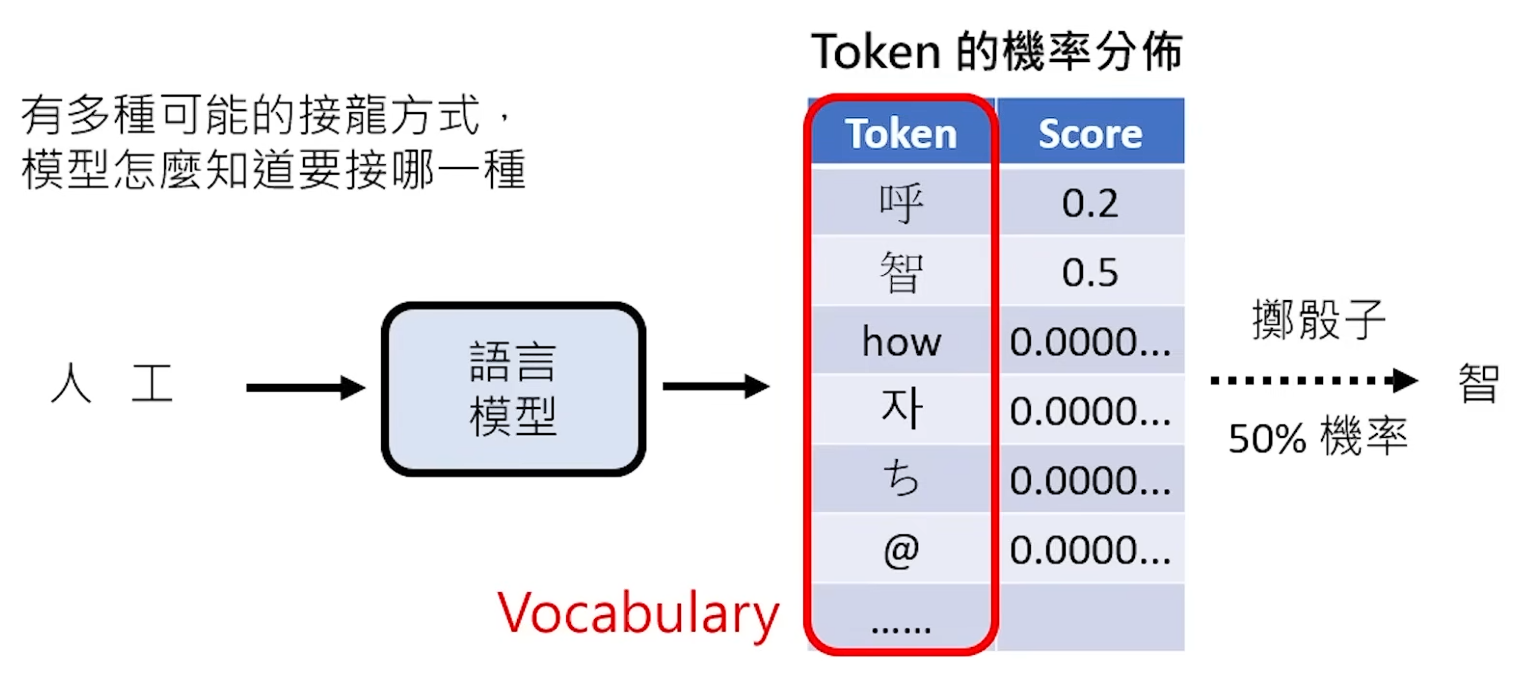
当有多个Token作为输出备选时,AI会给备选Token打出不同的分数(分数越高概率越高),当完成分数平定之后AI会根据概率随机筛选出一个作为此次接龙的Token;所有备选Token的合集被称为vocabulary。
- 语言知识:如语法、词性
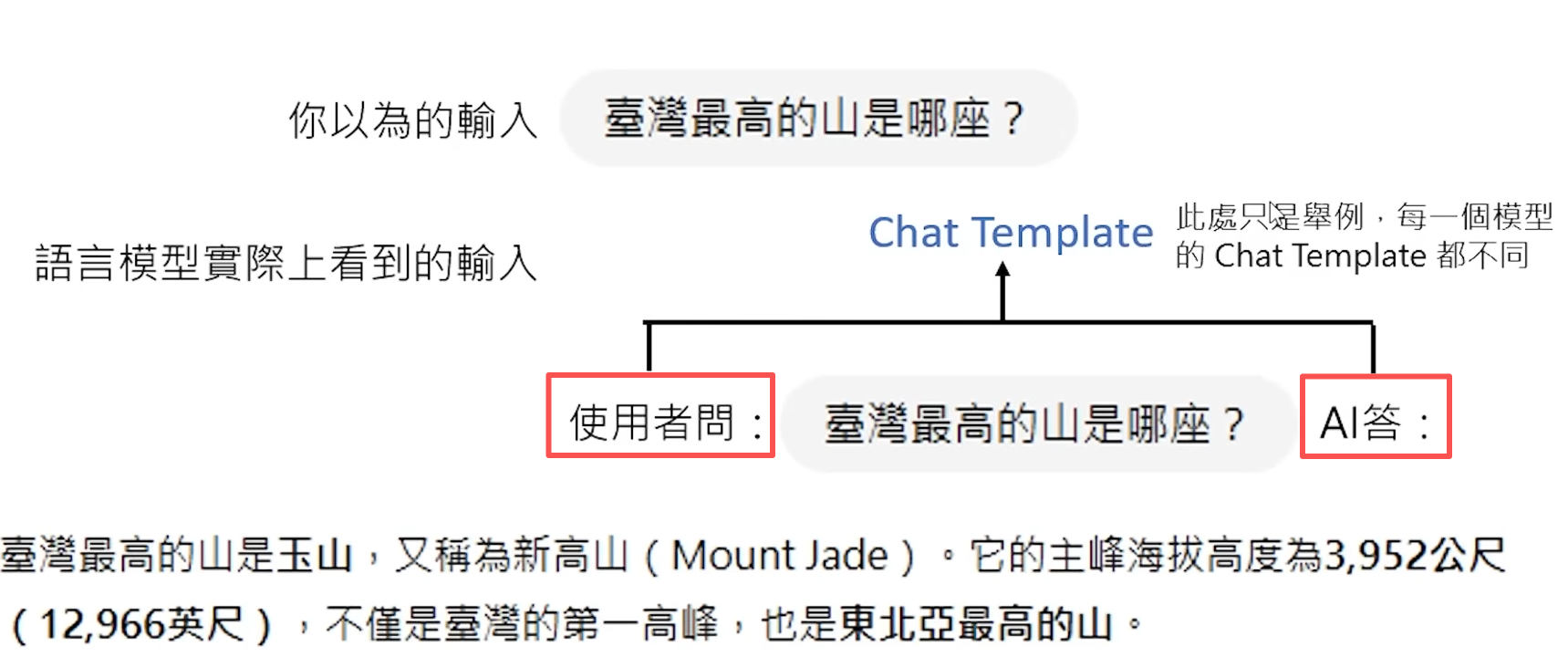
在真实的应用对话中,关于“台湾最高的山时哪座?”这个问题可以接龙多种正确答案,如:a.富士山 b.玉山 、那我去问谁呢 等 。为了让LLM输出正确的答案,应用通常会将用户输入的问题前后,补充额外的“Prompt”,这种“Prompt”被称为Chat Template
Prompt
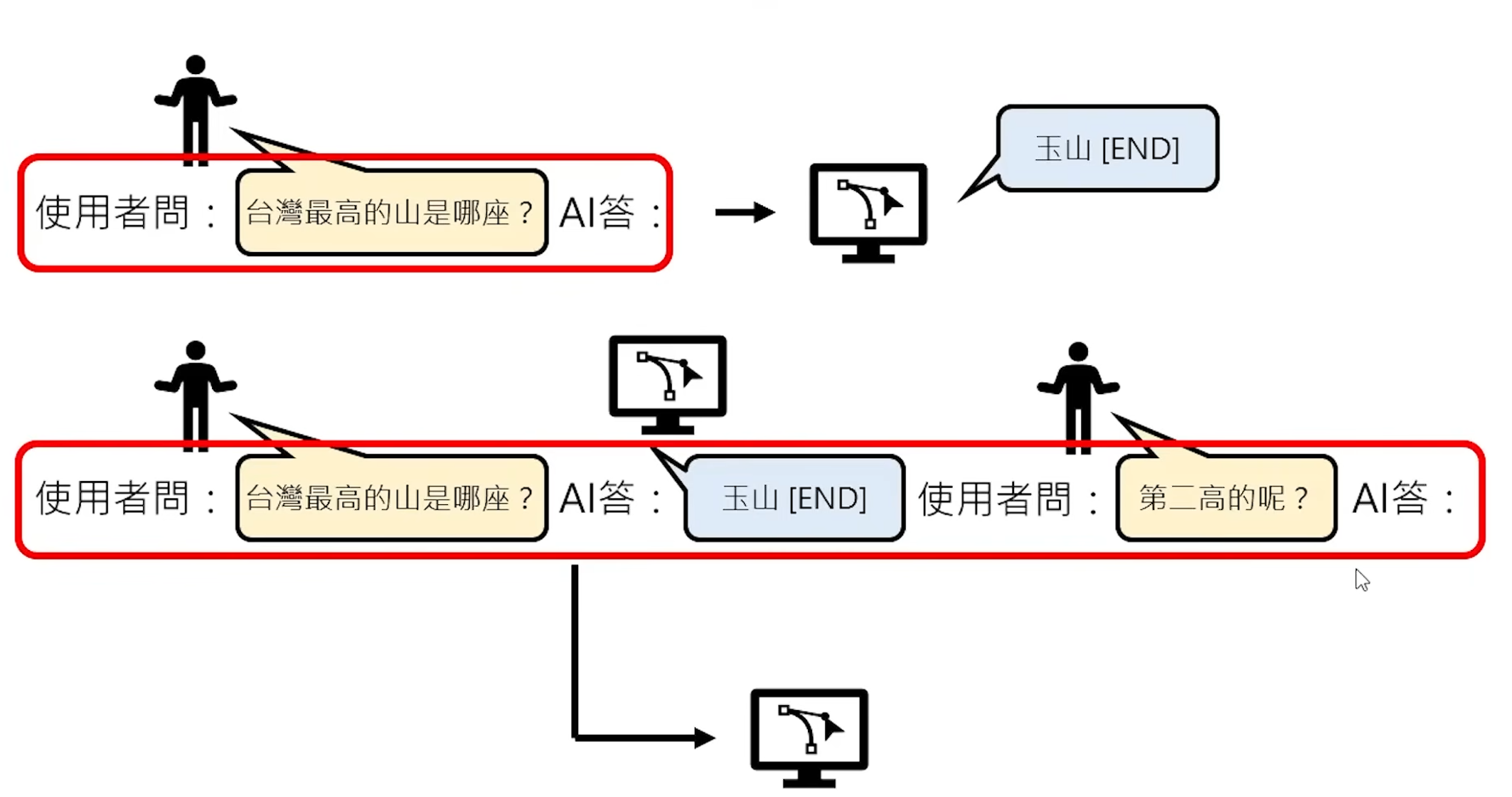
由于“接龙”的特性,往往AI会胡编乱造,这种情况被称为AI 幻觉
为了确保AI输出的正确性,人类应该确保输入的Prompt足够完整清晰(Context Engineering)
1.2 图像、音频生成原理
初期图像生成AI,将像素点作为“接龙”的Prompt;初期语音生成AI,将音频取样点作为“接龙”的Prompt。由于图片的像素以及音频取样点的“接龙”工程过于浩大,会将图片进行“压缩”处理,此“压缩”指的是将图片分割成16 * 16这种较大的取样块,将不同的取样块匹配为不同的符号(每个符号代表不同的图像内容,如毛茸茸,可爱),然后再将符号作为“接龙”的Prompt。
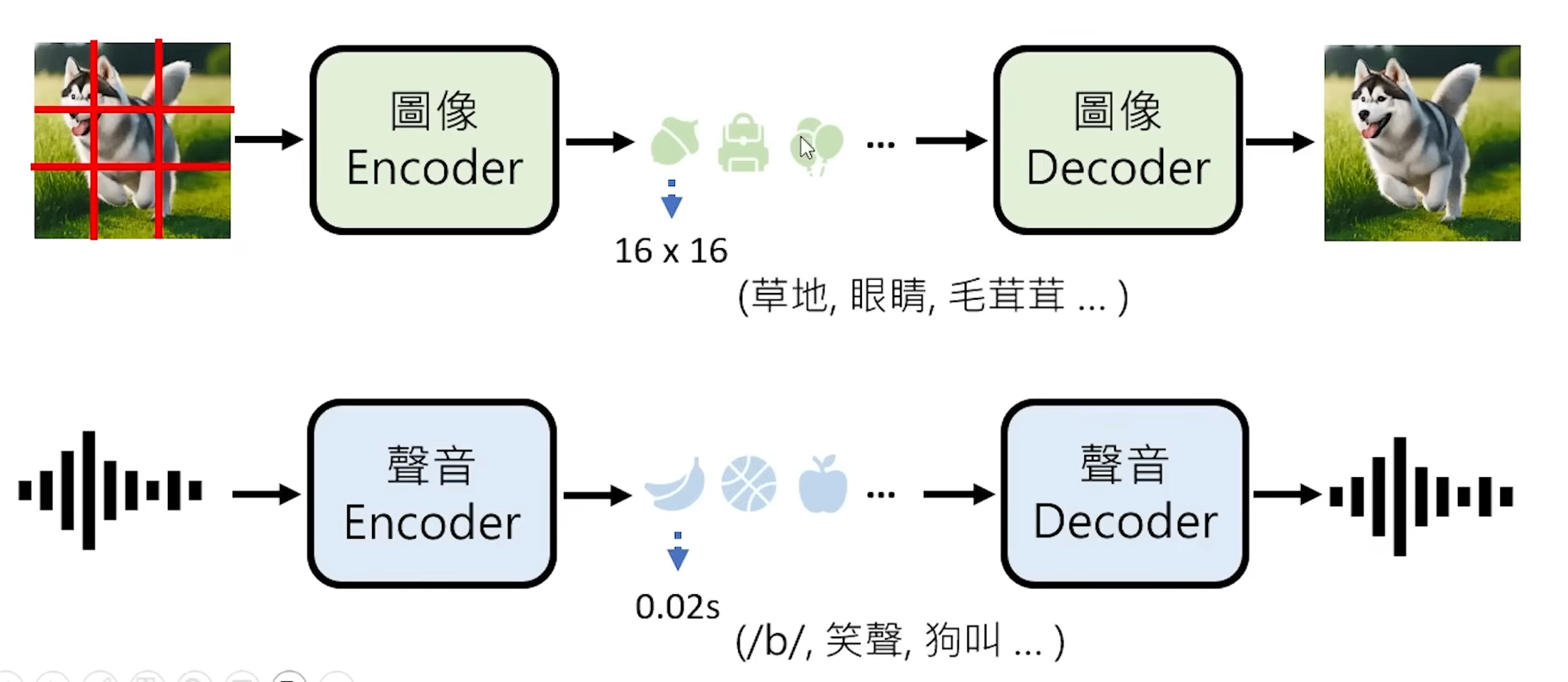
1.3 生成式AI原理
生成式AI本质就是让机器学会生成有限而有组件的物品
在AI语言模型中,预测每个Token的过程,都是从有限词汇表里做选择,本质上属于分类问题。

1.4 原理实践
移步云盘:第一节课.ipynb

没有回复内容