

源代码:
(如果浏览器有自动翻译功能的,先关闭自动翻译功能再浏览本帖子。)
import requests, argparse, sys, re
from requests.packages import urllib3
from urllib.parse import urlparse
from bs4 import BeautifulSoup
def parse_args():
parser = argparse.ArgumentParser(epilog='\tExample: \r\npython ' + sys.argv[0] + " -u http://www.baidu.com")
parser.add_argument("-u", "--url", help="The website")
parser.add_argument("-c", "--cookie", help="The website cookie")
parser.add_argument("-f", "--file", help="The file contains url or js")
parser.add_argument("-ou", "--outputurl", help="Output file name. ")
parser.add_argument("-os", "--outputsubdomain", help="Output file name. ")
parser.add_argument("-j", "--js", help="Find in js file", action="store_true")
parser.add_argument("-d", "--deep",help="Deep find", action="store_true")
return parser.parse_args()
# Regular expression comes from https://github.com/GerbenJavado/LinkFinder
def extract_URL(JS):
pattern_raw = r"""
(?:"|') # Start newline delimiter
(
((?:[a-zA-Z]{1,10}://|//) # Match a scheme [a-Z]*1-10 or //
[^"'/]{1,}\. # Match a domainname (any character + dot)
[a-zA-Z]{2,}[^"']{0,}) # The domainextension and/or path
|
((?:/|\.\./|\./) # Start with /,../,./
[^"'><,;| *()(%%$^/\\\[\]] # Next character can't be...
[^"'><,;|()]{1,}) # Rest of the characters can't be
|
([a-zA-Z0-9_\-/]{1,}/ # Relative endpoint with /
[a-zA-Z0-9_\-/]{1,} # Resource name
\.(?:[a-zA-Z]{1,4}|action) # Rest + extension (length 1-4 or action)
(?:[\?|/][^"|']{0,}|)) # ? mark with parameters
|
([a-zA-Z0-9_\-]{1,} # filename
\.(?:php|asp|aspx|jsp|json|
action|html|js|txt|xml) # . + extension
(?:\?[^"|']{0,}|)) # ? mark with parameters
)
(?:"|') # End newline delimiter
"""
pattern = re.compile(pattern_raw, re.VERBOSE)
result = re.finditer(pattern, str(JS))
if result == None:
return None
js_url = []
return [match.group().strip('"').strip("'") for match in result
if match.group() not in js_url]
# Get the page source
def Extract_html(URL):
header = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.108 Safari/537.36",
"Cookie": args.cookie}
try:
raw = requests.get(URL, headers = header, timeout=3, verify=False)
raw = raw.content.decode("utf-8", "ignore")
return raw
except:
return None
# Handling relative URLs
def process_url(URL, re_URL):
black_url = ["javascript:"]# Add some keyword for filter url.
URL_raw = urlparse(URL)
ab_URL = URL_raw.netloc
host_URL = URL_raw.scheme
if re_URL[0:2] == "//":
result = host_URL + ":" + re_URL
elif re_URL[0:4] == "http":
result = re_URL
elif re_URL[0:2] != "//" and re_URL not in black_url:
if re_URL[0:1] == "/":
result = host_URL + "://" + ab_URL + re_URL
else:
if re_URL[0:1] == ".":
if re_URL[0:2] == "..":
result = host_URL + "://" + ab_URL + re_URL[2:]
else:
result = host_URL + "://" + ab_URL + re_URL[1:]
else:
result = host_URL + "://" + ab_URL + "/" + re_URL
else:
result = URL
return result
def find_last(string,str):
positions = []
last_position=-1
while True:
position = string.find(str,last_position+1)
if position == -1:break
last_position = position
positions.append(position)
return positions
def find_by_url(url, js = False):
if js == False:
try:
print("url:" + url)
except:
print("Please specify a URL like https://www.baidu.com")
html_raw = Extract_html(url)
if html_raw == None:
print("Fail to access " + url)
return None
#print(html_raw)
html = BeautifulSoup(html_raw, "html.parser")
html_scripts = html.findAll("script")
script_array = {}
script_temp = ""
for html_script in html_scripts:
script_src = html_script.get("src")
if script_src == None:
script_temp += html_script.get_text() + "\n"
else:
purl = process_url(url, script_src)
script_array[purl] = Extract_html(purl)
script_array[url] = script_temp
allurls = []
for script in script_array:
#print(script)
temp_urls = extract_URL(script_array[script])
if len(temp_urls) == 0: continue
for temp_url in temp_urls:
allurls.append(process_url(script, temp_url))
result = []
for singerurl in allurls:
url_raw = urlparse(url)
domain = url_raw.netloc
positions = find_last(domain, ".")
miandomain = domain
if len(positions) > 1:miandomain = domain[positions[-2] + 1:]
#print(miandomain)
suburl = urlparse(singerurl)
subdomain = suburl.netloc
#print(singerurl)
if miandomain in subdomain or subdomain.strip() == "":
if singerurl.strip() not in result:
result.append(singerurl)
return result
return sorted(set(extract_URL(Extract_html(url)))) or None
def find_subdomain(urls, mainurl):
url_raw = urlparse(mainurl)
domain = url_raw.netloc
miandomain = domain
positions = find_last(domain, ".")
if len(positions) > 1:miandomain = domain[positions[-2] + 1:]
subdomains = []
for url in urls:
suburl = urlparse(url)
subdomain = suburl.netloc
#print(subdomain)
if subdomain.strip() == "": continue
if miandomain in subdomain:
if subdomain not in subdomains:
subdomains.append(subdomain)
return subdomains
def find_by_url_deep(url):
html_raw = Extract_html(url)
if html_raw == None:
print("Fail to access " + url)
return None
html = BeautifulSoup(html_raw, "html.parser")
html_as = html.findAll("a")
links = []
for html_a in html_as:
src = html_a.get("href")
if src == "" or src == None: continue
link = process_url(url, src)
if link not in links:
links.append(link)
if links == []: return None
print("ALL Find " + str(len(links)) + " links")
urls = []
i = len(links)
for link in links:
temp_urls = find_by_url(link)
if temp_urls == None: continue
print("Remaining " + str(i) + " | Find " + str(len(temp_urls)) + " URL in " + link)
for temp_url in temp_urls:
if temp_url not in urls:
urls.append(temp_url)
i -= 1
return urls
def find_by_file(file_path, js=False):
with open(file_path, "r") as fobject:
links = fobject.read().split("\n")
if links == []: return None
print("ALL Find " + str(len(links)) + " links")
urls = []
i = len(links)
for link in links:
if js == False:
temp_urls = find_by_url(link)
else:
temp_urls = find_by_url(link, js=True)
if temp_urls == None: continue
print(str(i) + " Find " + str(len(temp_urls)) + " URL in " + link)
for temp_url in temp_urls:
if temp_url not in urls:
urls.append(temp_url)
i -= 1
return urls
def giveresult(urls, domian):
if urls == None:
return None
print("Find " + str(len(urls)) + " URL:")
content_url = ""
content_subdomain = ""
for url in urls:
content_url += url + "\n"
print(url)
subdomains = find_subdomain(urls, domian)
print("\nFind " + str(len(subdomains)) + " Subdomain:")
for subdomain in subdomains:
content_subdomain += subdomain + "\n"
print(subdomain)
if args.outputurl != None:
with open(args.outputurl, "a", encoding='utf-8') as fobject:
fobject.write(content_url)
print("\nOutput " + str(len(urls)) + " urls")
print("Path:" + args.outputurl)
if args.outputsubdomain != None:
with open(args.outputsubdomain, "a", encoding='utf-8') as fobject:
fobject.write(content_subdomain)
print("\nOutput " + str(len(subdomains)) + " subdomains")
print("Path:" + args.outputsubdomain)
if __name__ == "__main__":
urllib3.disable_warnings()
args = parse_args()
if args.file == None:
if args.deep is not True:
urls = find_by_url(args.url)
giveresult(urls, args.url)
else:
urls = find_by_url_deep(args.url)
giveresult(urls, args.url)
else:
if args.js is not True:
urls = find_by_file(args.file)
giveresult(urls, urls[0])
else:
urls = find_by_file(args.file, js = True)
giveresult(urls, urls[0])
复制后文件后缀改为.py即可使用
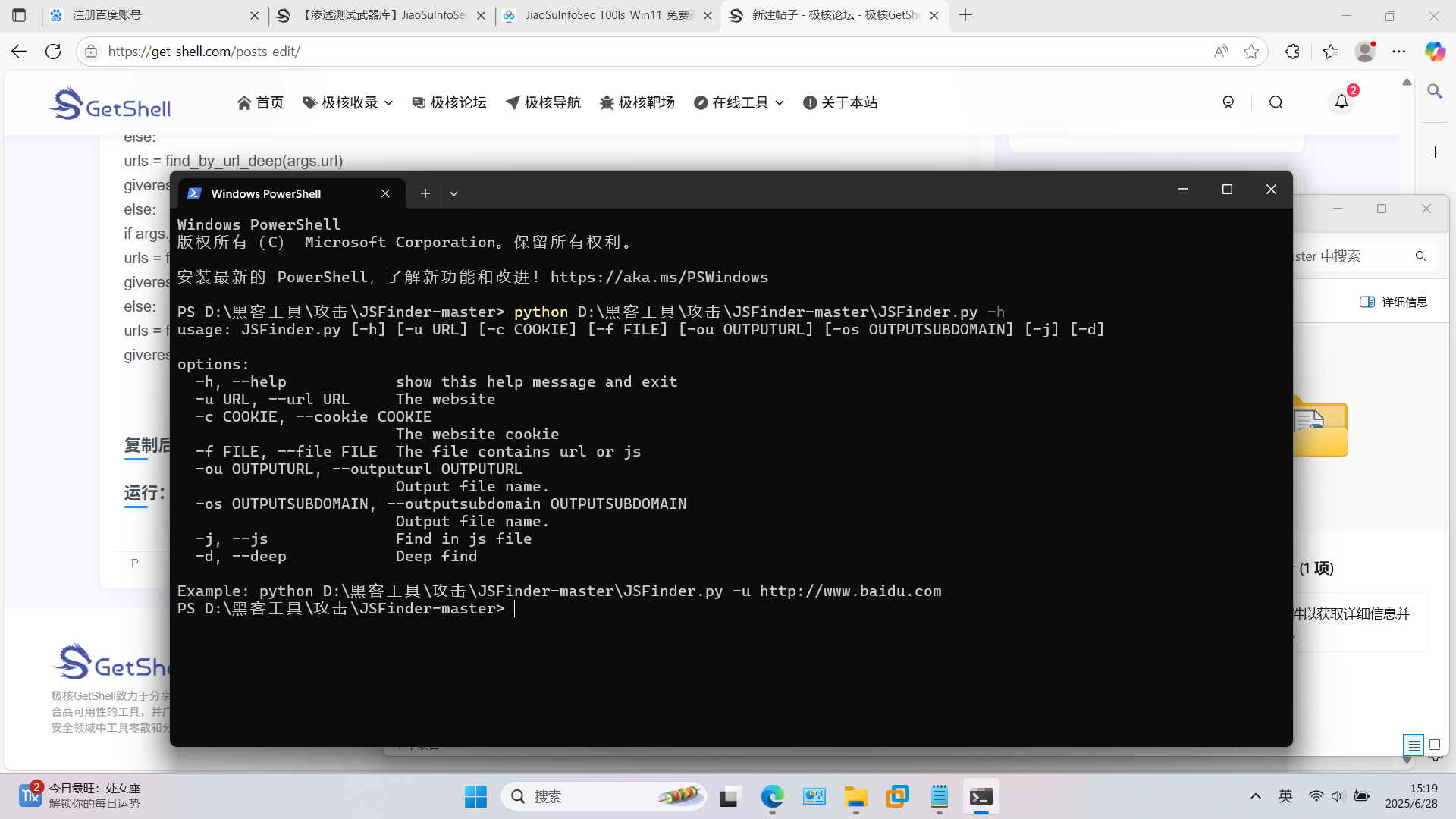
运行:
![表情[baoquan] - 极核GetShell](https://get-shell.com/wp-content/themes/zibll/img/smilies/baoquan.gif)
