
精 网安筑基篇-MySQL


本文为个人学习记录,由于我也是初学者可能会存在错误,如有错误请指正
附录、SQL命名规定和规范
0.1 命名规定

0.2 命名规范

一、数据定义语言DDL
主要完成数据库和表的管理,不涉及对数据的操作,而是关注数据库的结构和元数据。
1.1 库管理
1.1.1 库创建
- 创建数据库,使用默认的字符集和排序
CREATE DATABASE 数据库名; - 判断并创建默认字符集库
CREATE DATABASE IF NOT EXISTS 数据库名; - 创建指定字符集库或排列方式
CREATE DATABASE 数据库名 CHARACTER SET 字符集; CREATE DATABASE 数据库名 COLLATE 排序规则; - 创建指定字符集和排序规则库
CREATE DATABASE 数据库名 CHARACTER SET 字符集 COLLATE 排序规则;MySql8默认值
字符集:utfmb8
排序规则:utf8mb4_unicode_ci# 查看默认字符集和排序方式命令 SHOW VARIABLES LIKE ‘character_set_database’; SHOW VARIABLES LIKE ‘collation_database’;字符集和排序规则


1.1.2 库查看
使用和查看库,包括展示和切换库等命令
- 查看当前所有库
SHOW DATABASES; - 查看当前使用库
SELECT DATABASE(); - 查看指定库下所有表
SHOW TABLES FROM 数据库名; - 查看创建库的信息
SHOW CREATE DATABASE 数据库名; - 切换库/选中库
USE 数据库名;
1.1.3 库修改
- 修改库编码集
ALTER DATABASE 数据库名 CHARACTER SET 字符集; ALTER DATABASE 数据库名 COLLATE 排序方式; ALTER DATABASE 数据库名 CHARACTER SET 字符集 COLLATE 排序方式;
> 注意:
> 没有修改数据库名称的指令,修改数据库名称需要备份数据,删除旧库,创建新库
1.1.4 库删除
- 直接删除
DROP DATABASE 数据库名; - 判断删除库
DROP DATABASE IF EXISTS 数据库名;
1.2 表管理
1.2.1 数据类型
整数、浮点数、定点数、字符串、日期时间等
- 整数
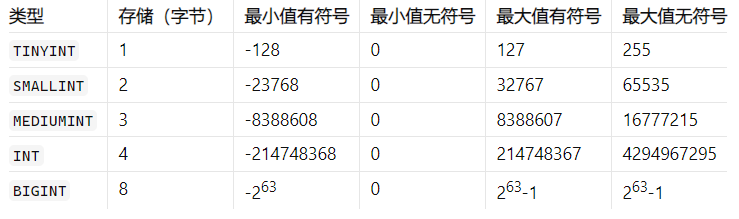
示例:
> 注意:标准的SQL语句中只包含:SMALLINT、INT 其他类型均为MYSQL专属
- 浮点数(低精度)

> 注意:
> 从MYSQL 8.0.17 开始不推荐使用非标准FLOAT(M,D) DOUBLE(M,D)
> 当使用无符号修饰时,只保留正值的范围 负值丢弃
示例:
stu_height float(4,1) unsigned COMMIT '只保留一位小数,进行四舍五入'- 定点数(高精度)

示例:
emp_salary DECIMAL(8,1) COMMIT '工资,只保留一位小数,四舍五入'- 字符串

> 注意:
> CHAR(M) 类型需要预先定义字符串长度。如果不指定长度,默认为1字符
> VARCHAR(M)类型必须指定长度,否则报错,4.0版本以下 指定的是字节,4.0版本以上指定的是字符 VARCHAR默认会增加一个字节,该字节用于字段存储是否为空
字符串超出限制的解决方案:
- 修改字符大小限制 m变小[不合理]
- 修改字符集[不合理]
- MySql中一行最大的限制为65535,除了(文本类型)TEXT(最大限制为65535) 或 BLOBS类型的列(不占有65535限制 法外狂徒)
示例:
name1 varchar(1600),
name1 TEXT- 文本类型
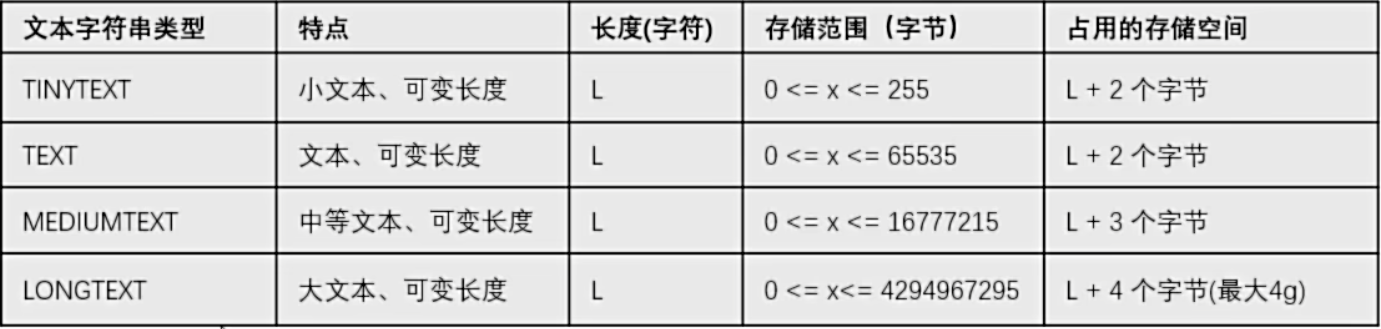
> 注意:
> 不推荐使用文本类型(性能非常差),推荐使用varchar记录文件地址
- 时间类型
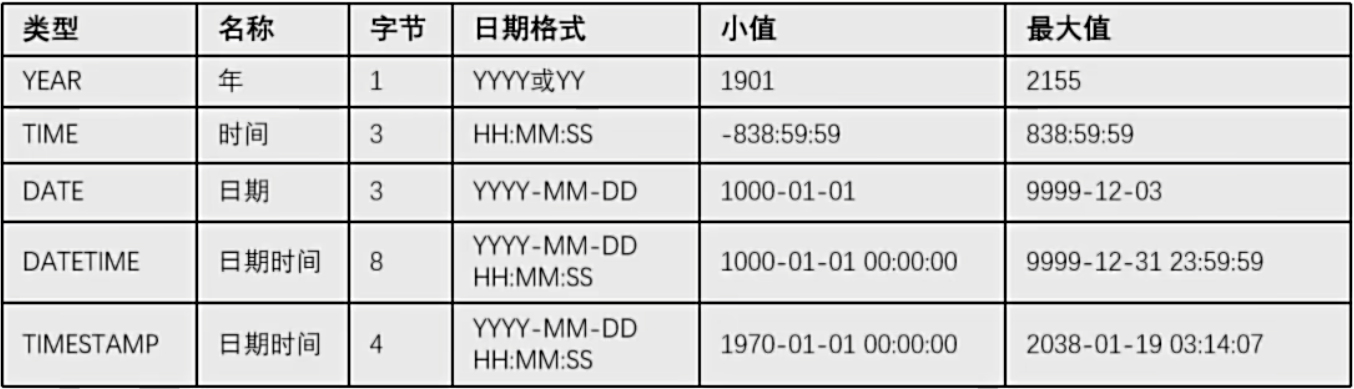
> 注意:
> year类型00-99值对应年限,[00-69]对应[2000-2069],[70-99]对应[1970-1999],建议四位年制
扩展:
- 插入时默认当前时间和修改时自动更新当前时间
ts TIMESTAMP DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP, DT DATETIME DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP - 插入时默认当前时间
ts TIMESTAMP DEFAULT CURRENT_TIMESTAMP, DT DATETIME DEFAULT CURRENT_TIMESTAMP
1.2.2 表创建
- 直接创建

- 判断创建

1.2.3 表修改
- 修改表中的列(字段)
# 修改表,添加一列[指定X字段之前或之后] ALTER TABLE 表名 ADD 字段名 字段类型 [FIRST|AFTER 字段名]; # 修改表,修改列名 ALTER TABLE 表名 CHANGE 原字段名 字段名 新字段类型 [FIRST|AFTER 字段名]; # 修改表,修改列类型 ALTER TABLE 表名 MODIFY 字段名 新字段类型 [FIRST|AFTER 字段名]; # 修改表,删除一列 ALTER TABLE 表名 DROP 字段名; - 修改表名
ALTER TABLE 表名 RENAME [TO] 新表名;
1.2.4 表删除
> 删除表和清空表无法回滚
- 删除数据表
DROP TABLE [IF EXISTS] 数据表1 [,数据表2,...]; -
清空表数据 (删除表中数据和关联记录)
TRUNCATE TABLE 表名;
二、数据操纵语言DML
插入、更新、删除操作 以行为基本单位
2.1 插入数据
- 为表的一行所有数据(列)插入数据
INSERT INTO 表名 VALUES (value1,value2,...); - 为表中的一行指定字段列插入数据
INSERT INTO 表名(列1,列2,...) VALUES (value1,value2,...); - 同时插入多条记录数据
INSERT INTO 表名 VALUES (value1,value2,...),...,(value1,value2,...); #或者 INSERT INTO 表名(列1,列2,...) VALUES (value1,value2,...),...,(value1,value2,...);
2.2 修改数据
- 修改表中的所有数据(全表修改)
UPDATE 表名 SET 列名1 = 值1,列名2 = 值2,...,列名 = 值 - 修改表中符合条件的数据(条件修改)
UPDATE 表名 SET 列名1 = 值1,列名2 = 值2,...,列名 = 值 [WHERE 条件]
2.3 删除数据
- 删除表中所有行数据(全表删除)
DELETE FROM 表名; - 删除表中符合条件行的数据(条件删除)
DELETE FROM 表名 [WHERE 条件];
三、数据查询语言DQL(单表)
查询操作 会基于原表数据查询出一个虚拟表
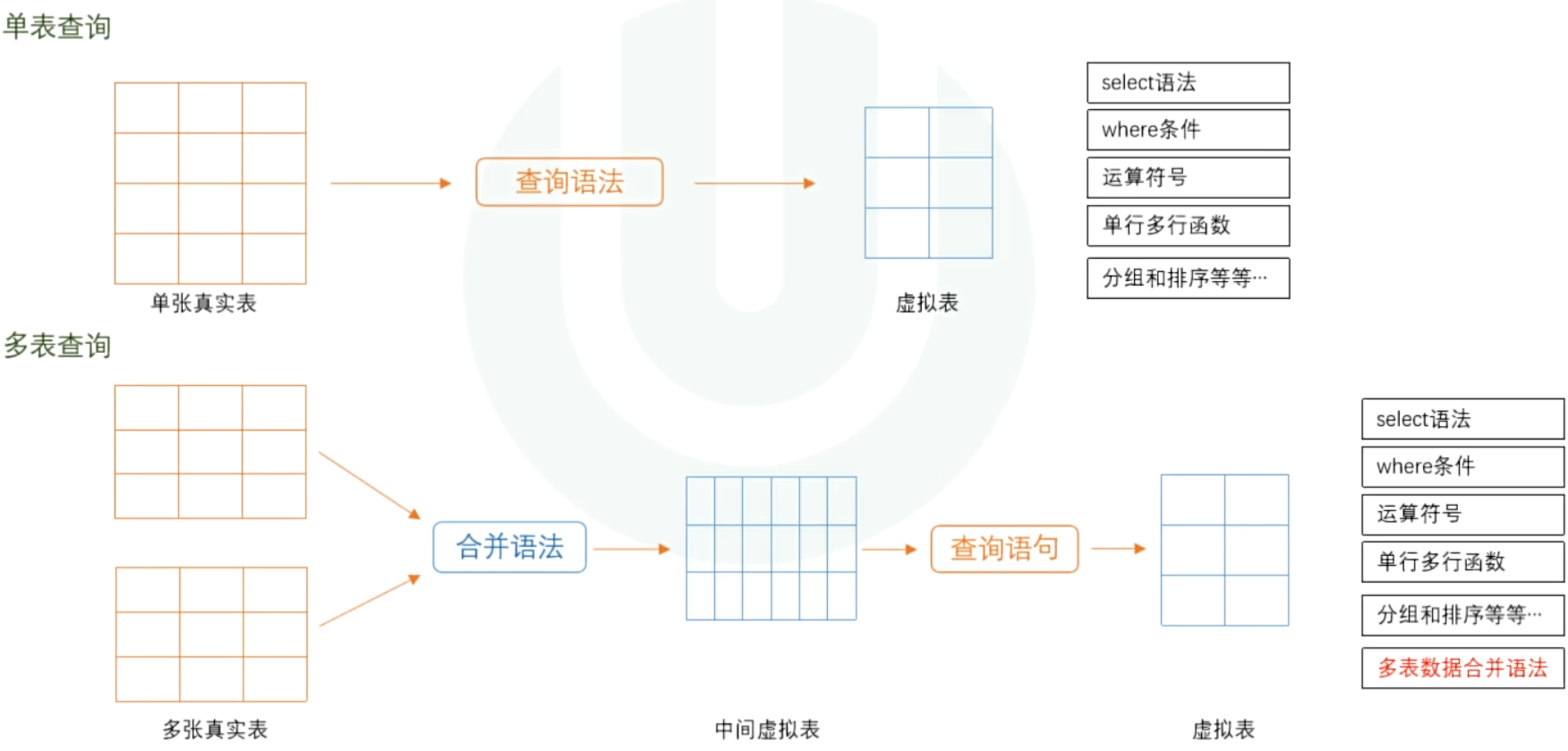
3.1 基础SELECT语法(不指定条件)
- 非表查询
SELECT 1; SELECT 9/2; SELECT VERSION(); - 指定表查询
SELECT 列名1,列名2,列名3 FROM 表名; # 或 SELECT 表名.列名1,表名.列名2,表名.* FROM 表名; - 起别名
SELECT 列名1 as 别名,列名2 as 别名,列名3 as 别名 FROM 表名; # 或 SELECT 列名1 别名,列名2 别名 FROM 表名; - 去除重复行
SELECT DISTINCT 列名1[,列名2...] FROM 表名; - 查询常数
# 每次查询都会多一列 corporation 值为 尚硅谷 SELECT '尚硅谷' as corporation ,列名,列名... FROM 表名;
3.2 表结构查询
- 查询表结构
DESCRIBE 表名 # 或 DESC 表名

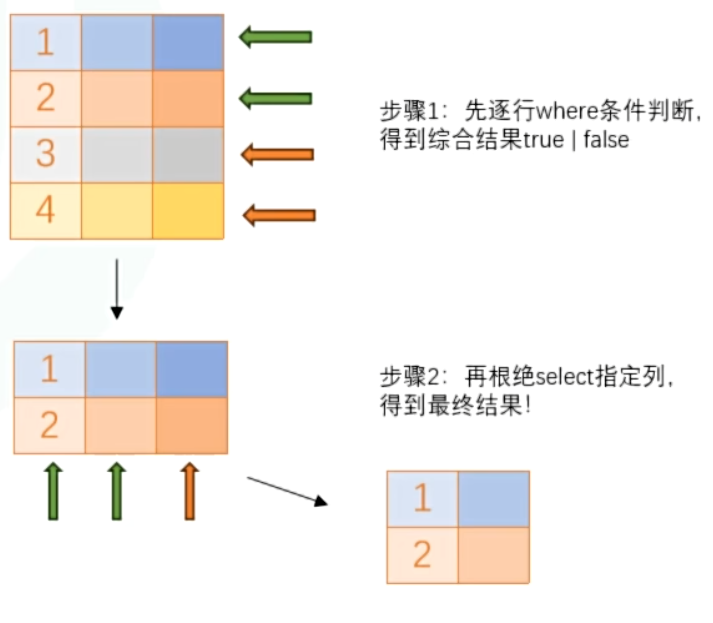
3.3 过滤数据(条件查询)
SELECT 字段1,字段2,...
FROM 表名
WHERE 过滤条件;> 先过滤再返回指定列,再选择指定列
3.4 运算符
3.4.1 算术运算符

> 注意:算术运算符可以运用到select列位置或where条件之后
示例:
SELECT 100,100 + 0,100 + 50 - 30,3 * 5,100/0 , 5 DIV 23.4.2 比较运算符
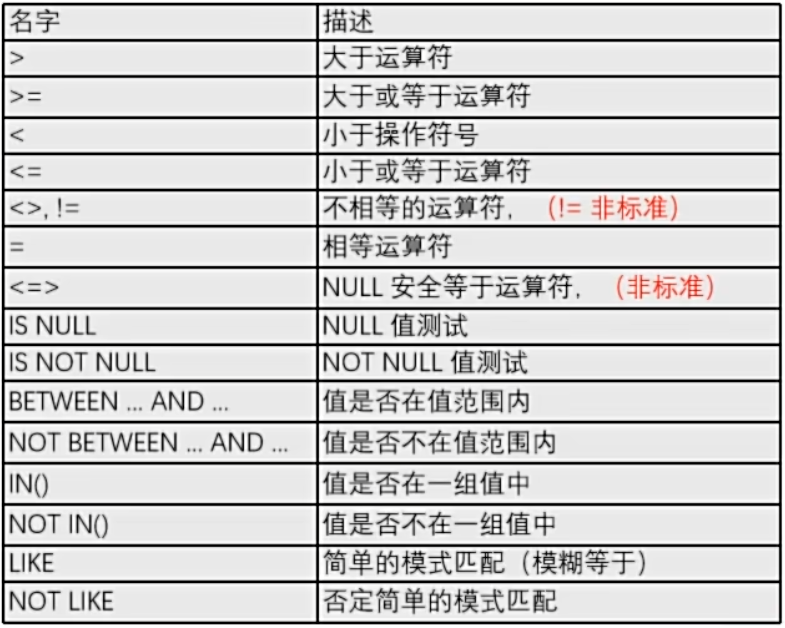
> 注意:
> 比较运算符的结果为 1 、 0 、null , 1 为 true , 0 和 null 为 false
> 当字符串和数字进行比较时 根据需要 字符串会转为数字 数字自动转为字符串
> 不需要考虑类型 ‘1’ = 1 为 true
示例:


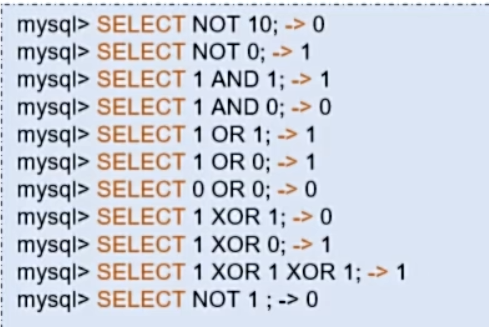
3.4.3 逻辑运算符

异或:两者不同即为1
示例:
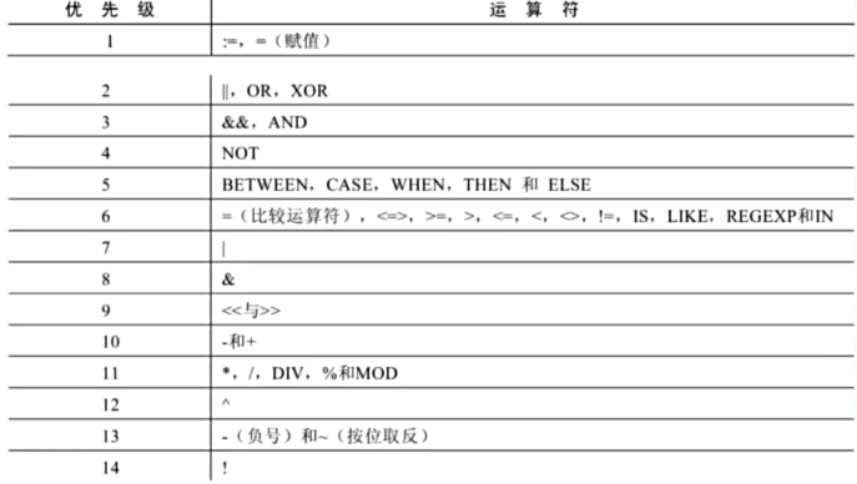
3.4.4 运算符优先级
从低到高
3.5 函数
函数分为内置函数和自定义函数
其中内置函数又分为单行函数和多行函数。
单行函数指的是对一行中某列进行操作的函数,返回结果为单一值;
多行函数指的是对多行中某列进行操作的函数,返回结果为单一值;
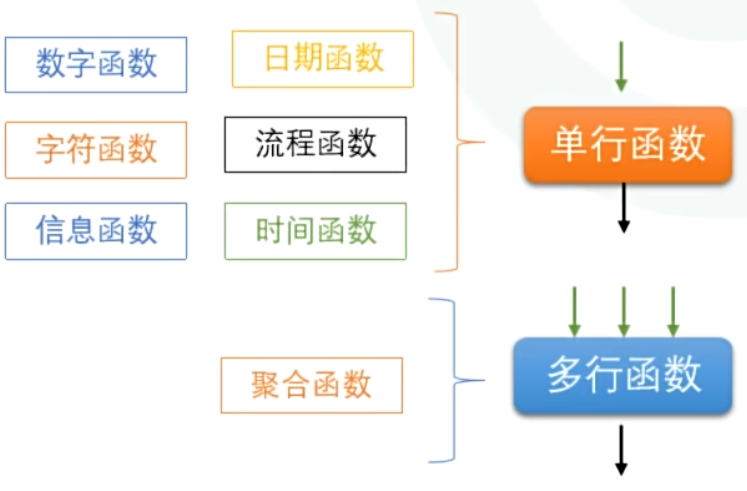
3.5.1 单行函数
- 数值函数
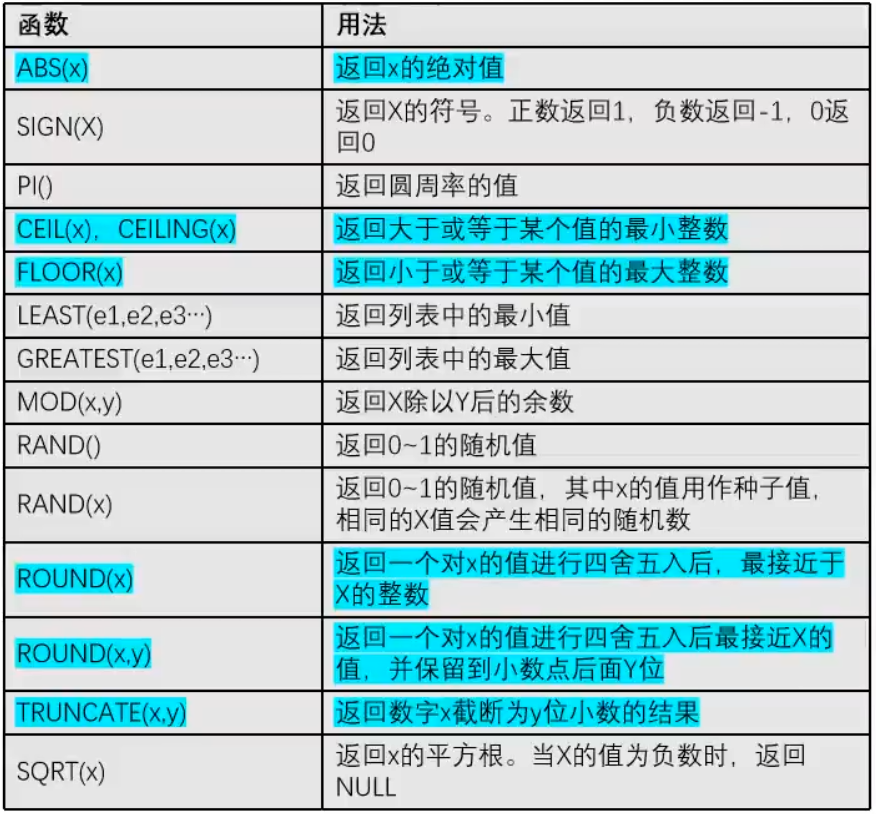
> 注意:
> round(x,y)会四舍五入 truncate(x,y)直接截取
示例:
SELECT ABS(-5),CEIL(4.5),FLOOR(4.5),TRUNCATE(RAND(),1),TRUNCATE(RAND(1),3),
TRUNCATE(RAND(1),3), ROUND(4.123426,5),TRUNCATE(4.123426,5);- 字符串函数
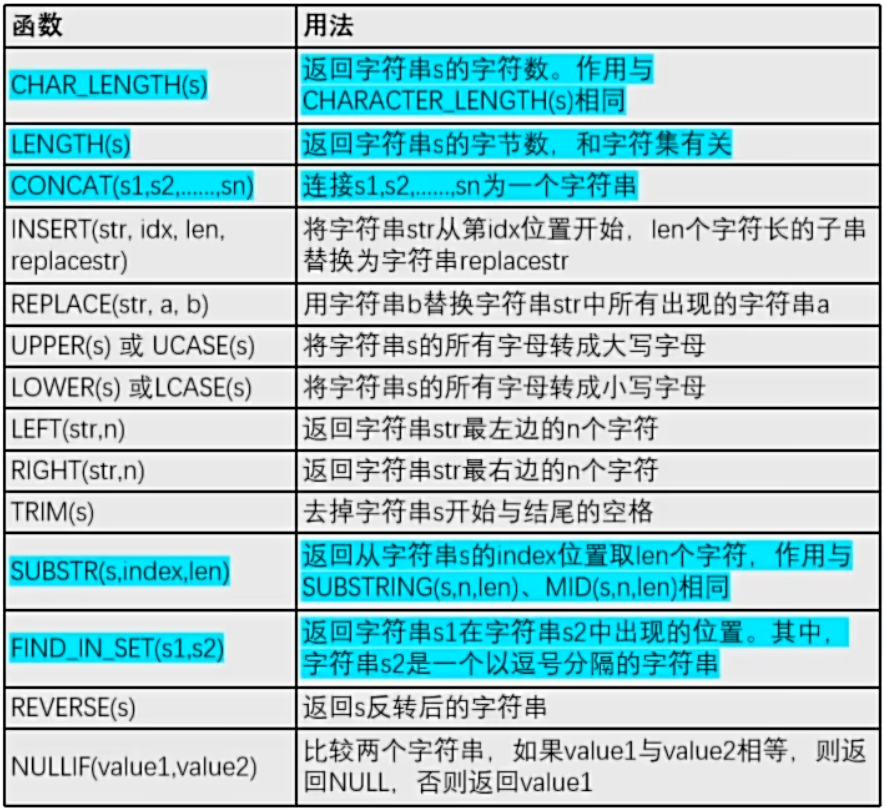
> 注意:
> MySql中,字符串的位置是从1开始的
示例:
SELECT CHAR_LENGTH('陈子豪'),LENGTH('陈子豪'),
CONCAT('Lu','Key','_C'),SUBSTR('test',1,2),FIND_IN_SET('d','d,a')- 时间函数
- 时间提取函数
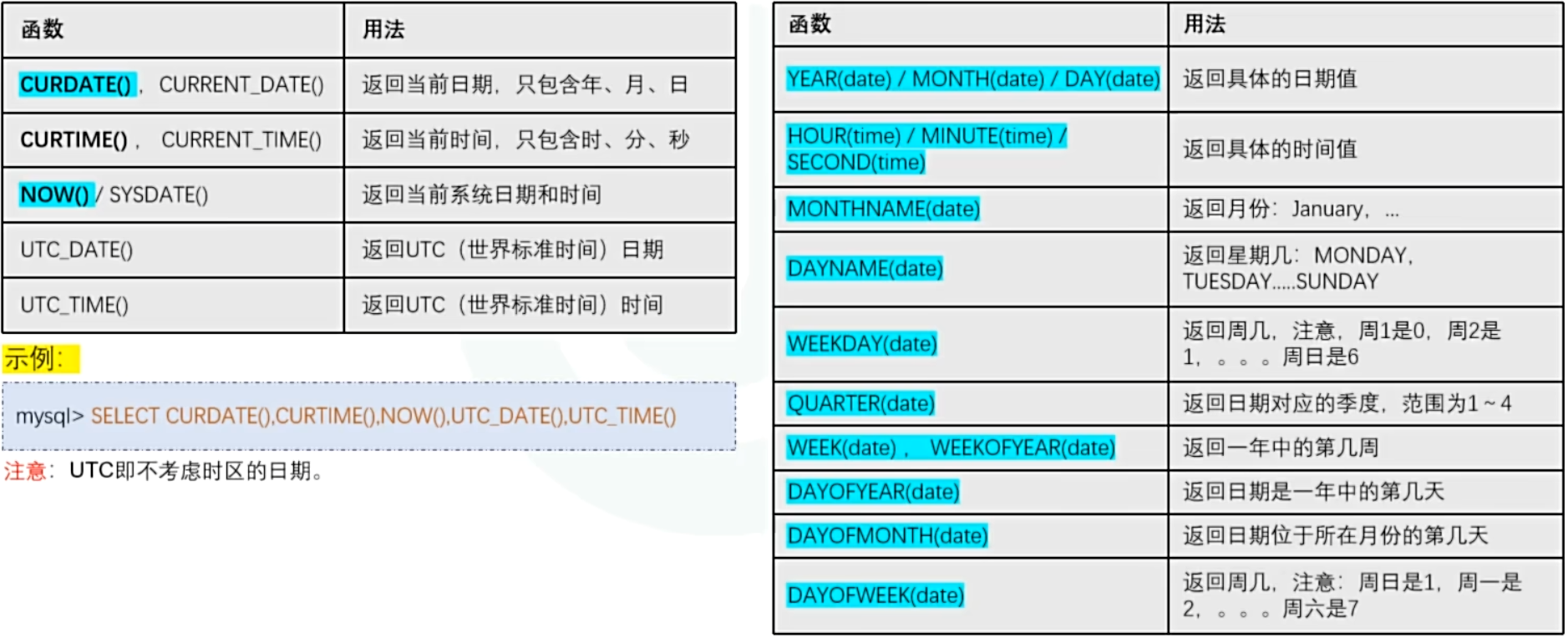
示例:
SELECT CURDATE(),NOW(),YEAR('2002-03-30'),MONTH('2002-03-30'),DAY('2002-03-30'),HOUR('24:50:59'),MINUTE('24:50:59'),SECOND('24:50:59'),
MONTHNAME('2002-03-30'),DAYNAME('2002-03-30'),WEEKDAY('2002-03-30'),QUARTER('2002-03-30'),WEEK('2002-03-30'),DAYOFYEAR('2002-03-30'),
DAYOFMONTH('2002-03-30'),DAYOFWEEK('2002-03-30');-
- 时间计算函数
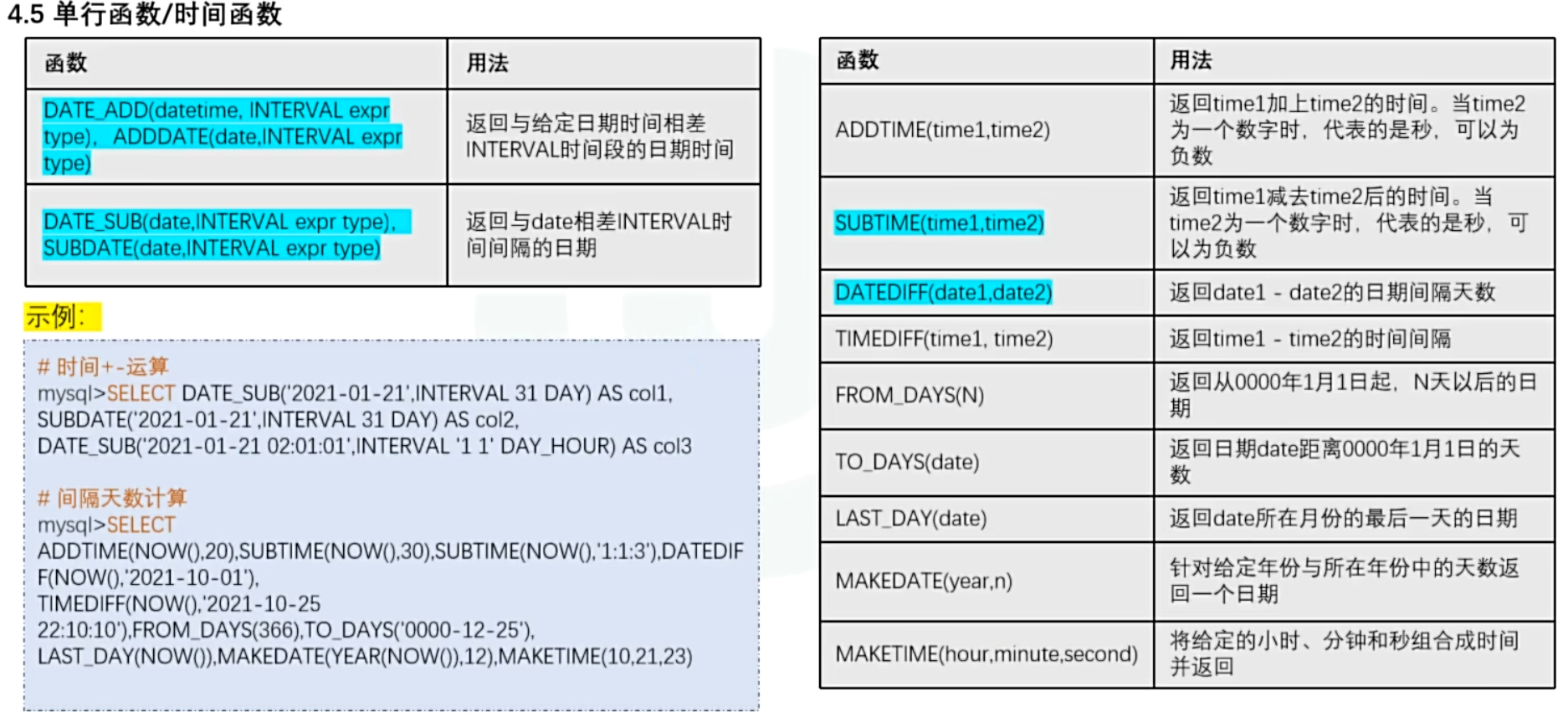
DATE_ADD以及DATE_SUB第二个参数中需要指定INTERVAL DAY HOUR YEAR MINUTE等时间单位,例:
SELECT MONTH(DATE_ADD(NOW(),INTERVAL 31 HOUR))-
- 时间格式化函数
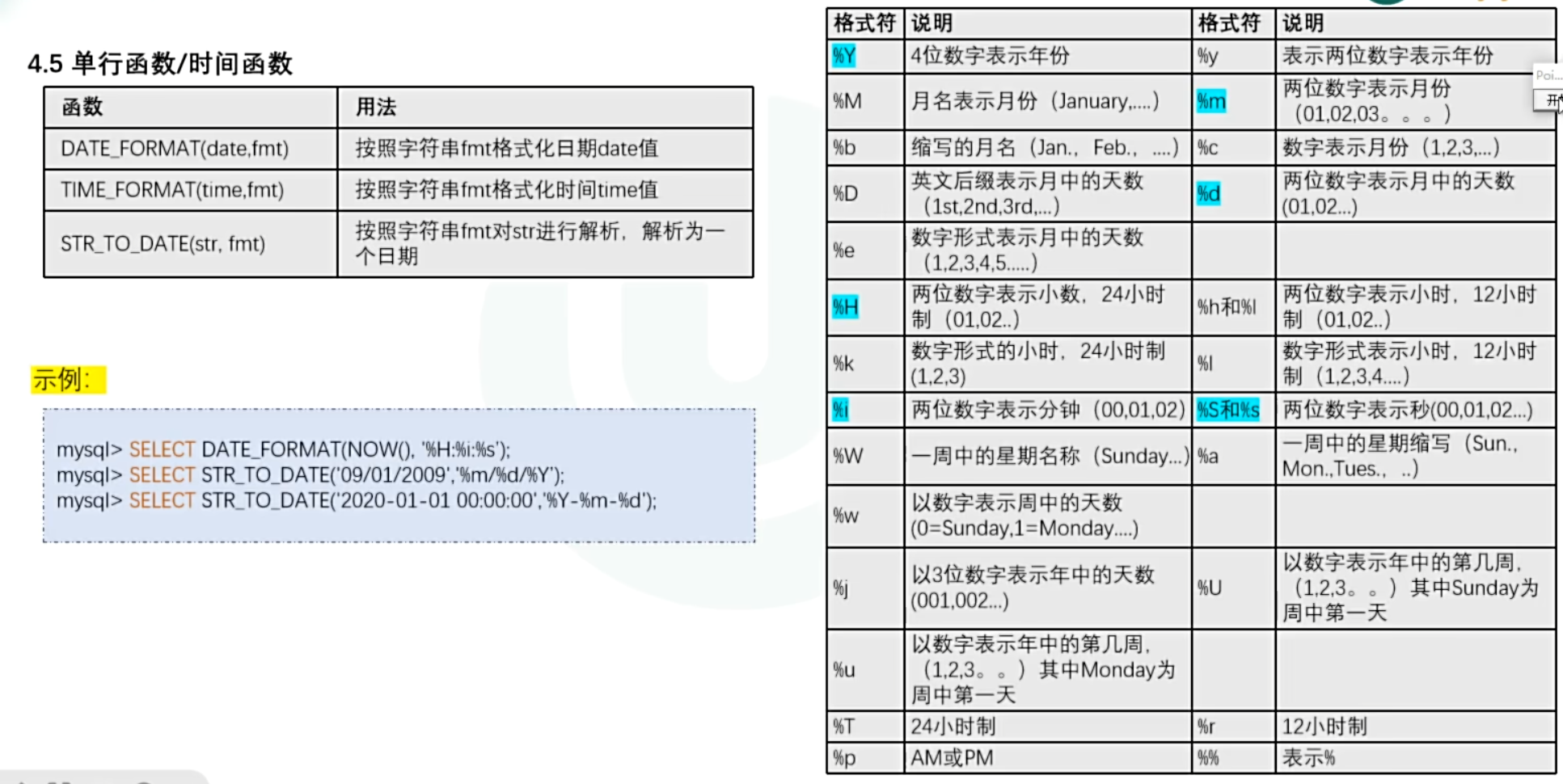
示例:
SELECT DATE_FORMAT(NOW(),'%m月%d日 %Y年 %H:%i:%s');> 注意:
> 时间标准格式为xxxx-xx-xx
> 如遇到非标准时间格式需要使用STR_TO_DATE转为标准字符串
示例:
SELECT DATEDIFF(NOW(),STR_TO_DATE('2002/03/30','%Y/%m/%d'));
SELECT DATEDIFF(NOW(),STR_TO_DATE('2002-03-30','%Y-%m-%d'));- 流程控制函数

示例:
SELECT birthday, salary ,
salary + salary * IF(YEAR(birthday)<1990,0.1,0.05) AS '涨薪之后'
FROM t_employee;

示例:
SELECT ename,gender,IFNULL(commission_pct,0.1) *
CASE gender
WHEN '男' THEN 2000
WHEN '女' THEN 3000
ELSE 0
END AS '补助金额'
FROM t_employee;3.5.2 多行函数
- 聚合函数
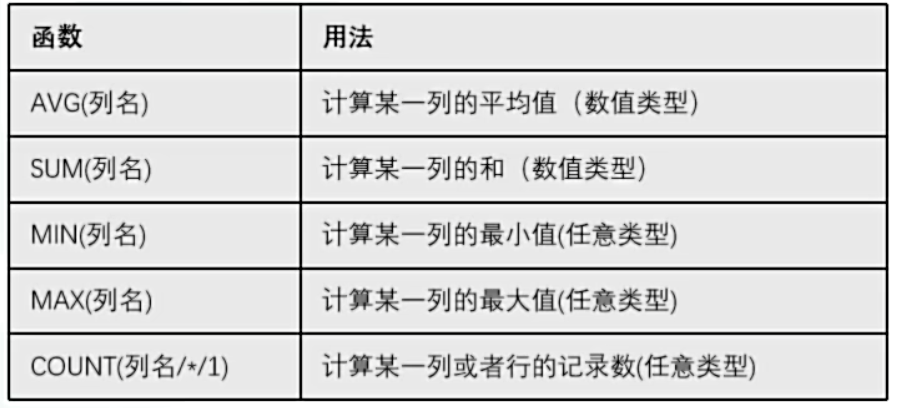
> 注意:
> 聚合函数不能嵌套使用 例:`AVG(SUM())`
3.6 高级查询
- 分组查询
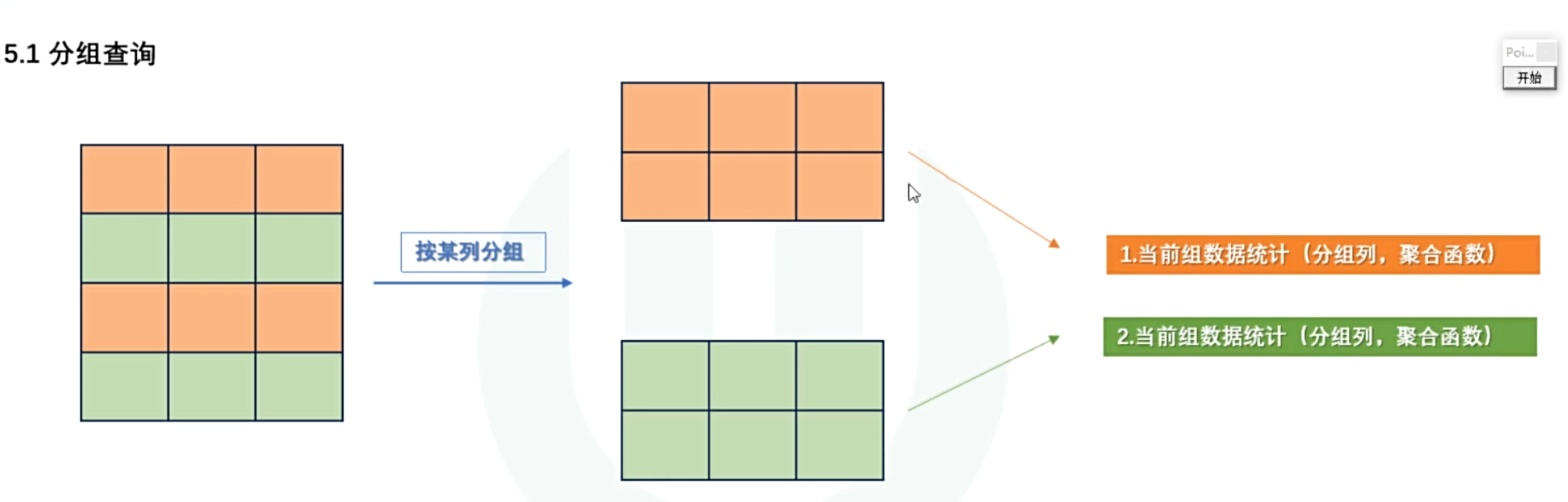
SELECT 分组列,分组列,聚合函数
FROM 表名
[WHERE 条件]
[GROUP BY 分组列,分组列 ... HAVING 分组后条件];
# having是分组后的条件 where是分组前的条件
# having只能在group by后面出现 where 随时可以出现
# having比较一般(99.999)都是聚合函数 where可以是任何参数的比较
# having可以使用select后面查询到的列的名称 || having在分组之后执行! 查询结果已经有了! 我们可以进行复用
# 而where不能复用select列 where早于select列名示例:
SELECT COUNT(*),gender
FROM t_employee
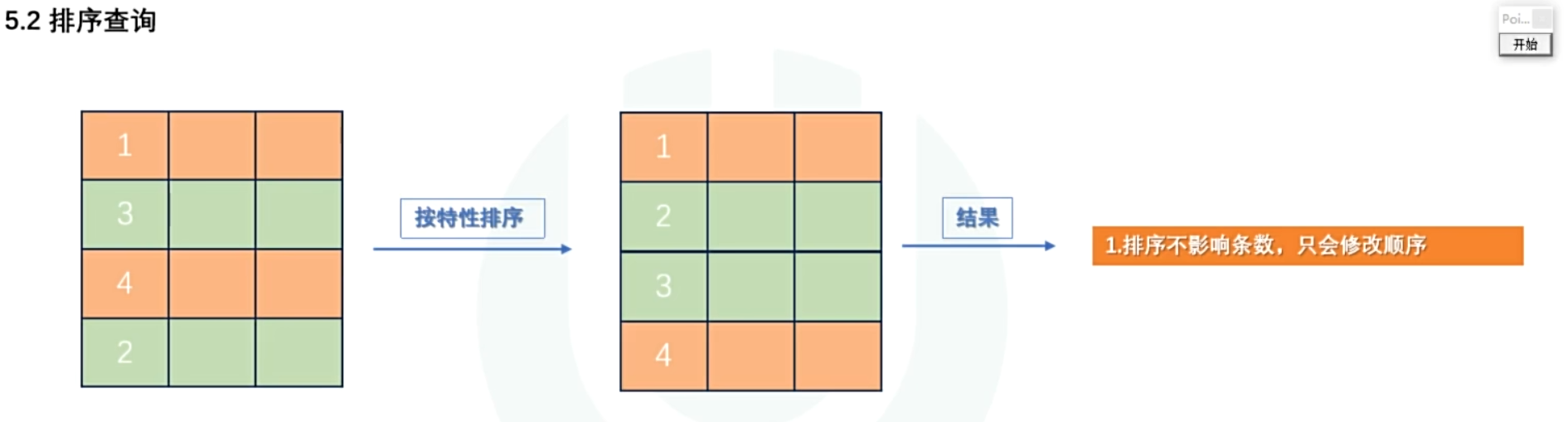
GROUP BY gender HAVING AVG(salary) > 5000;- 排序查询
SELECT 列,列,函数
FROM 表名
[WHERE 条件]
[ORDER BY 排序列 ASC | DESC ,排序列 ASC | DESC ...];ASC正序,DESC倒序
多列排序,只有第一列相同,第二列才会生效以此类推
- 数据分割(分页查询)
> 非标准SQL
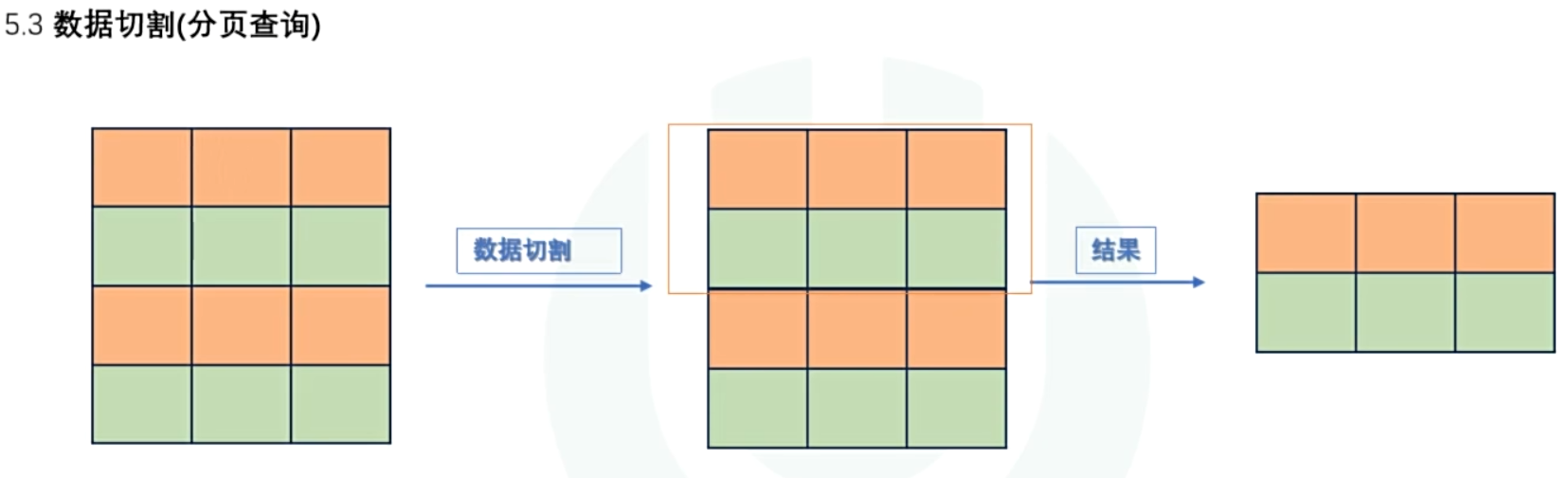
将结果进行分页切割,按照指定区域一段一段的进行展示,
例:商品分页展示,查询工资前三的员工
SELECT 列,列,函数
FROM 表名
[WHERE 条件]
[LIMIT [位置偏移量,]行数];行数:指示返回的记录条数
- SELECT 语句处理过程
关键字书写顺序:SELECT...FROM...WHERE...GROUP BY...HAVING...ORDER BY...LIMIT...
SELECT执行顺序:FROM -> WHERE -> GROUP BY -> HAVING -> SELECT -> ORDER BY -> LIMIT
> 注意:
> 标准SQL不允许再WHERE子句中引用列别名,
> 可以在GROUP BY、ORDER BY或HING子句中使用列别名。
- *补充
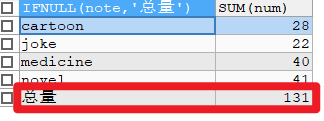
WITH ROLLUP子句用于汇总行
例:
统计每一种note的库存量,并合计总量
SELECT IFNULL(note,'总量'),SUM(num) FROM books GROUP BY note WITH ROLLUP;结果:
四、数据库约束
约束概念:表级别的规定,数据的限制语法
约束作用:确保数据的准确性、可靠性、正确性
添加时机:创建表、ALTER修改表结构
分类:

- (域)列级约束
- 非空约束
关键字:NOT NULL
创建表时添加:
CREATE TABLE 表名()
字段名 数据类型,
字段名 数据类型 NOT NULL,
字段名 数据类型 NOT NULL
);修改表结构添加:
ALTER TABLE 表名 MODIFY 字段名 数据类型 NOT NULL;删除:
ALTER TABLE 表名 MODIFY 字段名 数据类型 NULL;
# 或
ALTER TABLE 表名 MODIFY 字段名 数据类型;> 注意:
> 空串和0 不为NULL
-
- 默认值约束
关键字:DEFAULT
创建表时添加:
CREATE TABLE 表名()
字段名 数据类型,
字段名 数据类型 DEFAULT 默认值,
字段名 数据类型 NOT NULL DEFAULT 默认值
);修改表结构添加:
ALTER TABLE 表名 MODIFY 字段名 数据类型 DEFAULT 默认值;
#原字段包含 NOT NULL 修改时 需要加上NOT NULL
ALTER TABLE 表名 MODIFY 字段名 数据类型 DEFAULT 默认值 NOT NULL;删除:
ALTER TABLE 表名 MODIFY 字段名 数据类型;
# 原字段包含 NOT NULL 修改时 需要加上NOT NULL
ALTER TABLE 表名 MODIFY 字段名 数据类型 NOT NULL;-
- 检查约束
用于检查某个字段是否符合xx要求
> 8+版本新添加的特性
> 不推荐使用,建议使用程序级限制
关键字:CHECK(限制表达式)
创建表时添加:
CREATE TABLE 表名()
字段名 数据类型,
CHECK(表达式)
);示例:
CREATE TABLE IF NOT EXISTS emp3(
gender CHAR,
CHECK(gender IN ('男','女')),
age INT,
CHECK(age > 10)
);修改表结构添加:
ALTER TABLE 表名 ADD CONSTRAINT 约束名 CHECK(表达式);删除:
ALTER TABLE 表名 DROP CONSTRAINT 约束名;查看约束:
> MySQL自带的information_schema库中TABLE_CONSTRAINTS表中存放所有库的约束
SELECT *
FROM information_schema.TABLE_CONSTRAINTS
WHERE TABLE_SCHEMA = '数据库名' AND TABLE_NAME = '表名';结果:

4.1 (实体)行级约束
- 唯一约束
可以限制某个字段或组合字段,在表中的数据时唯一
关键字:UNIQUE (允许为空)
创建表时添加:
CREATE TABLE 表名(
字段名 数据类型 UNIQUE,
字段名 数据类型 UNIQUE KEY
);
# 或
CREATE TABLE 表名()
字段名 数据类型,
[CONSTRAINT 约束名] UNIQUE KEY(列名,列名)
);修改表结构添加:
ALTER TABLE 表名 ADD CONSTRAINT 约束名 UNIQUE KEY(列名,列名);删除:
ALTER TABLE 表名 DROP CONSTRAINT 约束名;- 主键约束
在任何情况下,主键列都可以确保唯一性
主键分为自定义主键(人为创建的一列)和自然主键(不是人为创建的列,数据列自带的属性列)
> 每个表中只能有一个主键
> 主键可以时单一列也可以时组合列
关键字:PRIMARY KEY
创建表时添加:
CREATE TABLE 表名(
字段名 数据类型 PRIMARY KEY,
字段名 数据类型
);
# 或
CREATE TABLE 表名(
字段名 数据类型,
字段名 数据类型,
[CONSTRAINT 约束名] PRIMARY KEY(字段名,字段名)
);修改表结构添加:
ALTER TABLE 表名 ADD PRIMARY KEY(字段名,字段名);删除:
ALTER TABLE 表名 DROP PRIMARY KEY;- 自增长约束
限定某个整数类型字段,插入数据时不显示维护,值自动增长
> 添加位置:只能添加到主键列或唯一约束列,普通列不可以
> 约束条件:每张表只能有一个自增长约束
> 特殊情况:如果给自增长字段设置0或null,列数据会自增长,如果设置非零非空,那么将真实设置值
关键字:AUTO_INCREMENT
创建表时添加:
CREATE TABLE 表名(
字段名 数据类型 PRIMARY KEY AUTO_INCREMENT
);
# 或
CREATE TABLE 表名(
字段名 数据类型 UNIQUE AUTO_INCREMENT
);修改表结构添加:
ALTER TABLE 表名 MODIFY 字段名 数据类型 AUTO_INCREMENT;删除:
ALTER TABLE 表名 MODIFY 字段名 数据类型;- (参照)外键约束
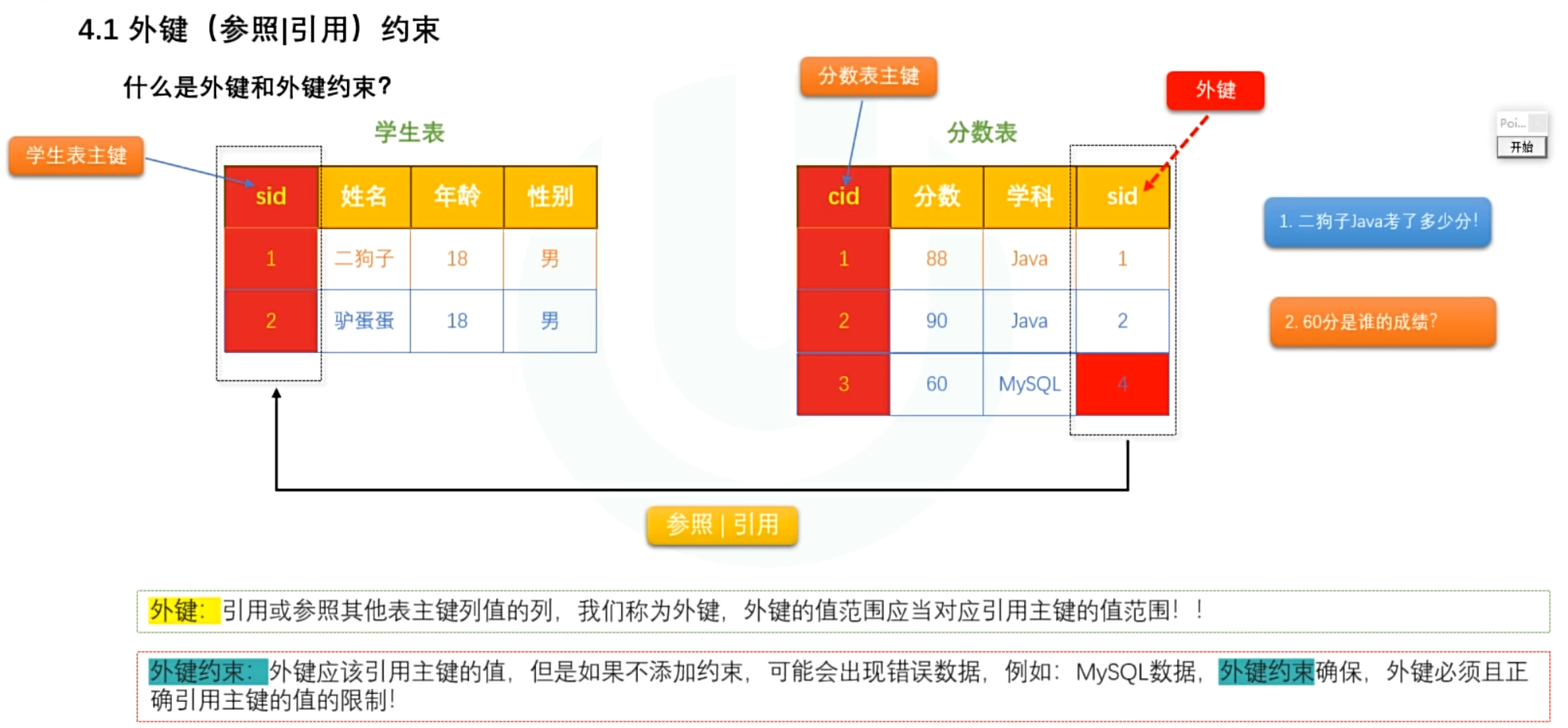
> 外键数量:每个表中可以包含多个外键
> 外键跨表:外键是跨表引用其他表的主键,被引用为主表,外键表为子表
> 外键类型:必须和主键类型保持一致
> 其他影响:在删除主表数据时,可能会因为子表引用而删除失败。可以删除子表的所有引用数据再删除
建表时添加:
#主表
CREATE TABLE 表名(
字段名 数据类型 PRIMARY KEY
);
#子表
CREATE TABLE 子表名(
字段名 数据类型 PRIMARY KEY,
[CONSTRAINT 约束名] FOREIGN KEY(外键) REFERENCES 主表名(主键) [ON UPDATE XXX][ON DELETE XXX]
);修改表结构添加:
ALTER TABLE 子表名 ADD [CONSTRAINT 约束名] FOREIGN KEY(子表字段) REFERENCES 主表名(主键) [ON UPDATE XXX][ON DELETE XXX];删除:
# 第一步查看约束名和删除外键约束
SELECT *
FROM information_schema.TABLE_CONSTRAINTS
WHERE TABLE_NAME = '子表名';
ALTER TABLE 子表名 DROP FOREIGN KEY 外键约束名;
# 第二步查看索引和删除外键索引
SHOW INDEX FROM 子表名;
ALTER TABLE 子表名 DROP INDEX 索引名;- 级联操作

五、多表关系
两表之间的关系具体分为三种:一对一、一对多、多对多,必须双向查看
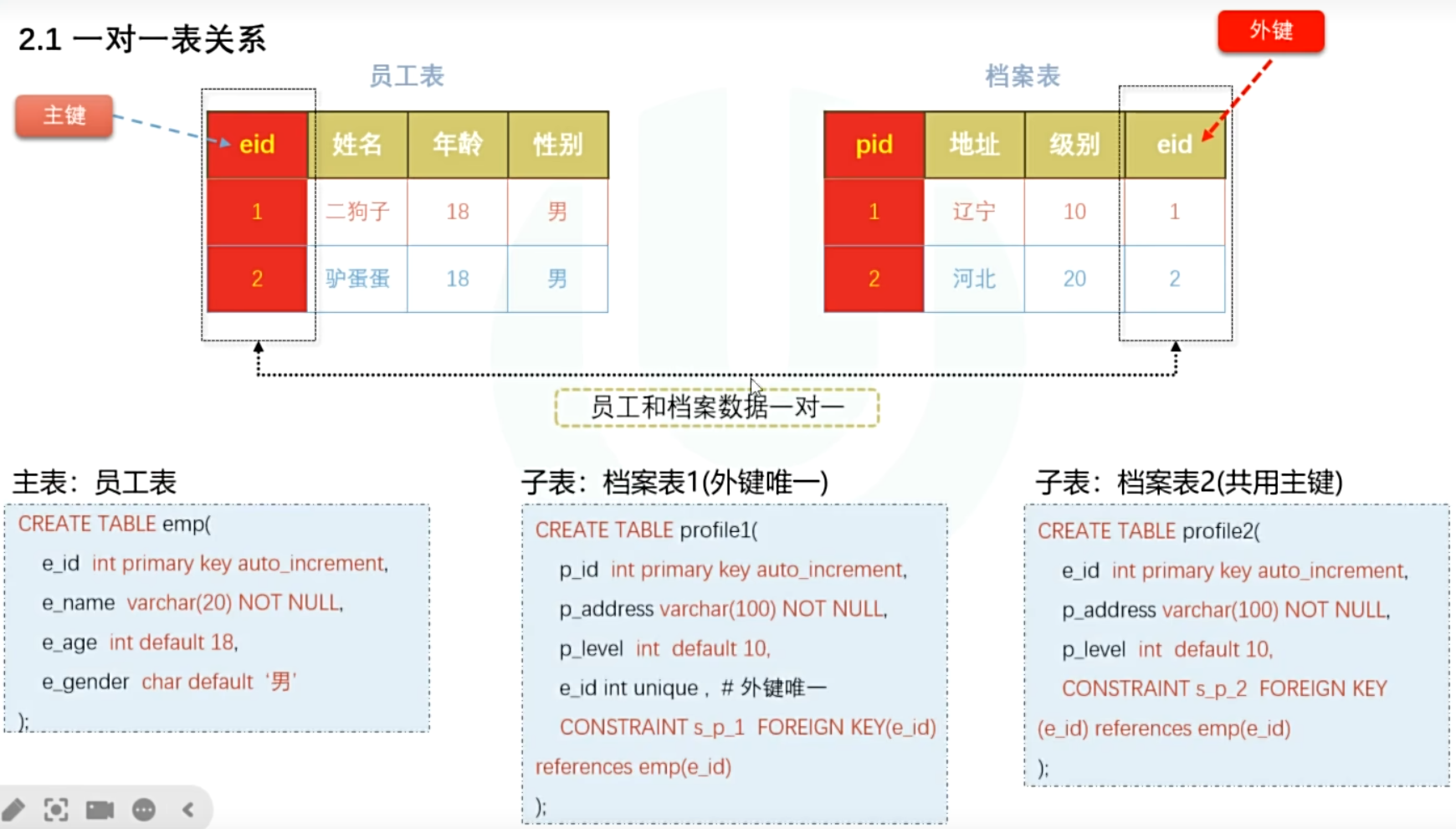
- 一对一
> 一对一不解决数据冗余问题
> 一对一存在的意义:一张表存储热数据,另一张表存冷数据,提高查询速度
> 一对一关系维护:子表外键对应的数据不能重复(外键唯一约束 UNIQUE 或 主子表共用主键)
示例:
- 一对多
> 一对一可以解决数据冗余的问题
> 一对一存在的意义:一个实体对应多个子元素,通过分表,解决数据冗余并提高数据操作效率
> 一对一关系维护:子表外键对应的数据可以重复(外键不唯一[正常创建主子表,添加外键约束即可])
示例:

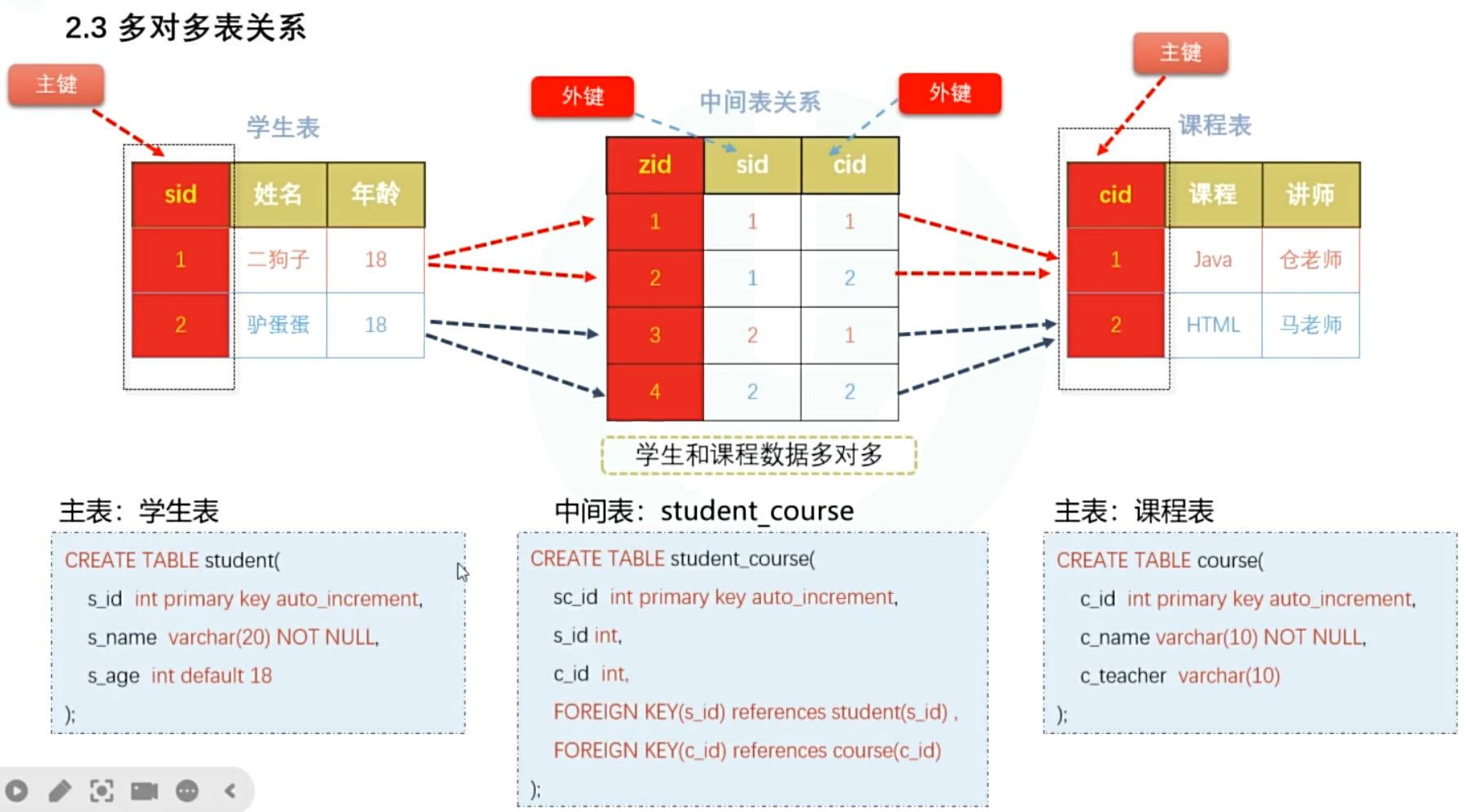
- 多对多
> 多对多特殊情况:多对多需要创建中间表建立数据之间的关联
> 多对多关系维护:中间表包含两个外键,主表数据之间间接关联
示例:
六、数据查询语言DQL(多表)
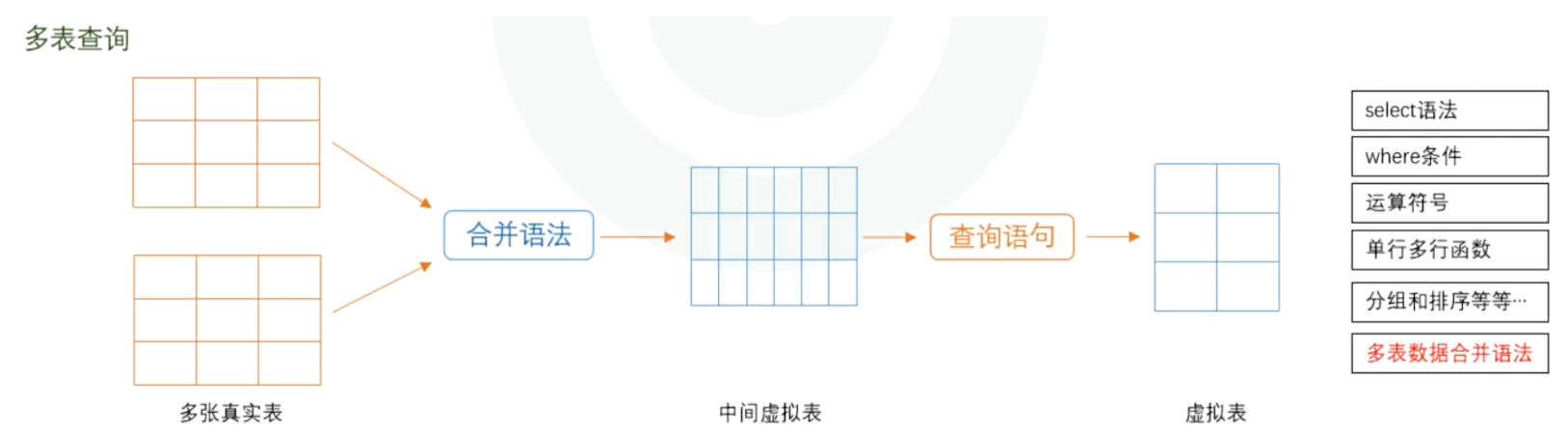
多表查询的重点是将多表数据利用多表查询语法合并单张虚拟表,按照多表合并的方向,可以分为:水平合并语法(主子表之间不需要主外键关联)和垂直合并语法(主子表之间需要主外键关联)
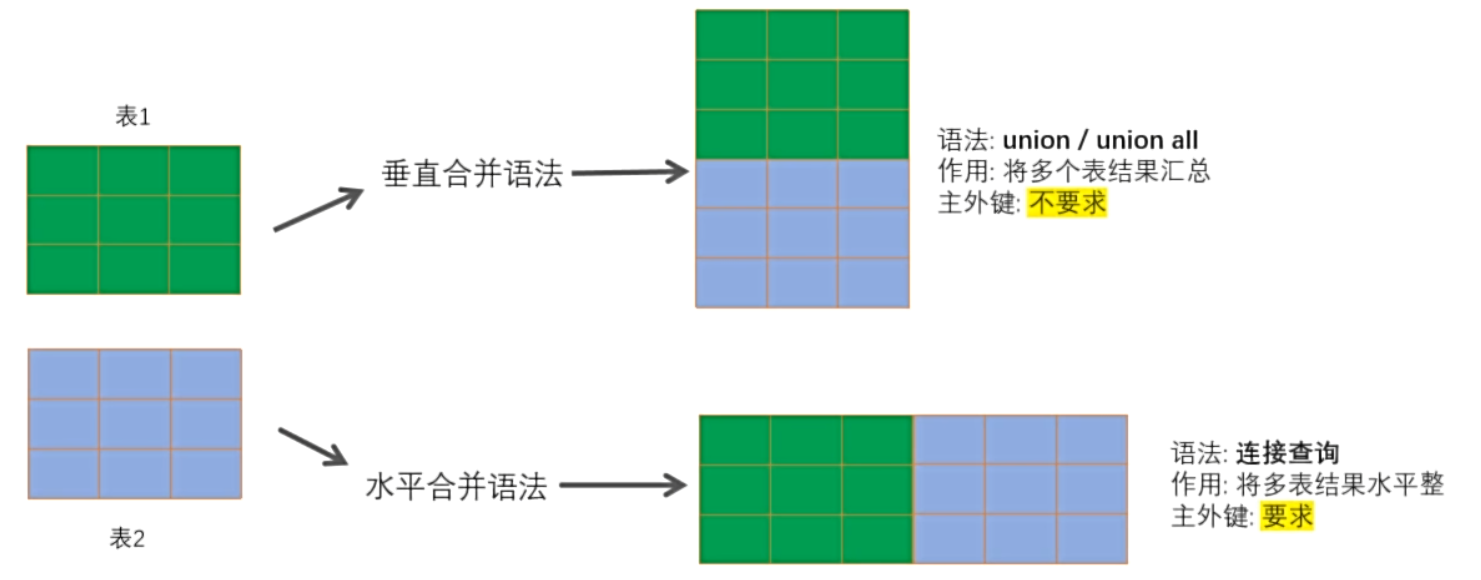
- 垂直合并语法
关键字:
UNION # 合并同时去除重复行
UNION ALL # 合并,不去除重复行> 实现要求:只要求合并的结果集之间的列数和对应列的数据类型相同即可
> 主外键要求:UNION只是结果集垂直汇总,不要求有主外键
示例:
# 创建表格 插入数据
CREATE TABLE a(
aid INT,
aname VARCHAR(10)
);
CREATE TABLE b(
bid INT,
bname VARCHAR(10)
);
INSERT INTO a VALUES(1,'aaaa'),(2,'bbbb'),(3,'cccc');
INSERT INTO b VALUES(4,'aaaa'),(5,'bbbb'),(6,'cccc');
# 使用UNION合并查询
SELECT * FROM a
UNION # 去除重复列
SELECT * FROM b;
SELECT * FROM a
UNION ALL # 不去除重复列
SELECT * FROM b;- 水平合并语法
> 核心要求:两个表之间必须有关系(主外键)
> 正确连接:判定主外键相等
-
- 内连接
> 必须存在主外键相等条件 不包含null
语法:
SELECT * FROM 表1 [INNER] JOIN 表2 ON 表1.主键 = 表2.外键 (标准)
SELECT ^ FROM 表1,表2 WHERE 表1.主键 = 表2.外键 (非标准)示例:
# 双表
SELECT e.eid,e.ename,d.did,d.dname
FROM t_employee e JOIN t_department d ON d.did = e.did
WHERE e.eid > 10;
# 多表 本质就是多个两表查询
SELECT e.eid , e.ename , e.did , d.did , d.dname , e.job_id , j.jname
FROM t_employee e
JOIN t_department d ON e.did = d.did
JOIN t_job j ON e.job_id = j.jid
WHERE e.eid > 10;-
- 外连接
外连接是一种用于从两个或多个表中检索数据的查询方式,与内连接不同的是,外连接会返回所有符合条件的行,同时还会返回未匹配的行。外连接分为左外(LEFT JOIN)、右外(RIGHT)
> 左右连接指的是指定一个逻辑主表,逻辑主表的数据一定能查的到
语法:
SELECT * FROM 表1(逻辑主表) LEFT [OUTER] JOIN 表2 ON 表1.主键 = 表2.外键 (左外)
SELECT * FROM 表1 RIGHT [OUTER] JOIN 表2(逻辑主表) ON 表1.主键 = 表2.外键 (右外)示例:
# 双表
SELECT e.eid,e.ename,IFNULL(d.did,'还未分配'),IFNULL(d.dname,'还未分配')
FROM t_employee e LEFT JOIN t_department d ON d.did = e.did;
# 多表
SELECT e.eid,e.ename, IFNULL(d.dname,'暂时未分配'),j.jname
FROM t_employee e
LEFT JOIN t_department d ON e.did = d.did
LEFT JOIN t_job j ON e.job_id = j.jid
WHERE e.eid > 10;-
- 自然连接
自然连接是一种内连接和外连接的升级版,会自动找到两个表中相同的列名,判定相同,可以省略ON 主 = 外的语法
语法:
SELECT * FROM 表1 NATURAL JOIN 表2; # 自然内连接
SELECT * FROM 表1 NATURAL LEFT JOIN 表2; # 自然左外连接
SELECT * FROM 表1 NATURAL RIGHT JOIN 表2; # 自然右外连接> 使用要求:主外键命名要相同,除了主外键命名要不同
> 使用USING指定数据表里的`同名字段`进行等值连接,例:
> employee e JOIN departments d USING(department_id);
-
- 自连接
自连接指的是在数据库中,一个表与自身进行连接的操作。自连接不是新的语法,就是单张表进行多次使用的一种场景。
示例:
SELECT e.eid,e.ename,e.mid,e2.ename
FROM t_employee e LEFT JOIN t_employee e2 ON e.mid = e2.eid;- 子查询
子查询指的是在SQL语句中嵌套了另一个完整的SELECT语句,这嵌套查询通常被称为子查询或内部查询
标量子查询: 返回结果是一行一列,单个值,一般用于条件判定
行子子查询: 返回结果是一行多列,一般用于或者插入数据的值,或者整体对比
列子子查询: 返回结果是多行单列,一般用于条件对比,需要配合in any all等关键字
表子子查询: 返回结果是多行多列,不能用于条件,一般用于查询的虚拟的中间表
- update 嵌套子查询
> 注意以下情况:
> update占用了员工表的引用(再获取) || 内部又要查询员工表的引用(先获取) [其中任何一方都不能直接修改]
UPDATE t_employee
SET salary = (SELECT salary FROM t_employee WHERE ename='孙红梅')
WHERE ename = '李冰冰';
错误代码: 1093
You can’t specify target table ‘t_employee’ for update in FROM clause
解决方法:释放内部占用,将内层的子查询,再嵌套一层子查询,释放原有表的引用即可
UPDATE t_employee
SET salary = (SELECT salary FROM (SELECT salary FROM t_employee WHERE ename='孙红梅') AS temp)
WHERE ename = '李冰冰';- delete 嵌套子查询
错误代码: 1093
You can’t specify target table ‘t_employee’ for update in FROM clause
解决方法:释放内部占用,将内层的子查询,再嵌套一层子查询,释放原有表的引用即可
- insert 嵌套子查询
- 复制某个表结构 创建新表
CREATE TABLE 新表名 LIKE 被复制结构的表名;-
- 使用INSERT语句+子查询,复制数据,此时INSERT不用写values
INSERT INTO 被插入数据的表名 (SELECT * FROM 被复制数据的表名);-
- 同时复制表结构+数据 [创建表并复制数据]
CREATE TABLE 新表名 AS (SELECT * FROM 被复制的表名)七、数据库高级和新特性
7.1 事务
> 注意:事务不支持DDL
数据库事务是一套操作数据命令的有序集合,一个不可分割的工作单位
事务中单个命令不会立即改变数据库数据,当内部全部命令执行成功,统一更新数据,当有任意命令失败,可以进行状态回滚。
事务作用:
1.为数据库操作序列提供了一个从失败中恢复正常状态的方法。
2.当多个应用程序在并发访问数据库时,以防止彼此的操作互相干扰。

1. 事务的开启、提交回滚
MySQL默认状态下是自动提交事务。
默认每一条语句都是一个独立的事务,一旦成功就提交了。语句报错就回滚
我们的目标:将多条语句加入到一个事务中
- 手动提交模式
# 开启手动提交事务模式(取消自动提交事务)
set autocommit = false; 或 set autocommit = 0; (单次连接临时生效)
上方语句执行之后,它之后的所有sql,都需要手动提交才生效
# 恢复自动提交模式
set autocommit = true; 或 set autocommit = 1;
# 查看是否自动提交
SHOW VARIABLES LIKE 'autocommit';示例:
SET autocommit = FALSE; (单次连接临时生效)
UPDATE `t_employee`
SET salary = 16000
WHERE ename = '刘烨';
COMMIT; # 提交
ROLLBACK; # 回滚- 开启独立事务
# 开启一个事务
start transaction;
{SQL语句}
{SQL语句}
{SQL语句}
COMMIT; # 提交
ROLLBACK; # 回滚示例:
start transaction; # 开启事务
update t_employee set salary = 0 where ename = '李冰冰';
# 未提交不生效
COMMIT; # 提交
ROLLBACK; # 回滚> 注意:事务不支持DDL
2. 事务隔离性概述
一个事务内部的操作及使用的数据对并发的其他事务时隔离的,并发执行的各个事务之间不能互相干扰。
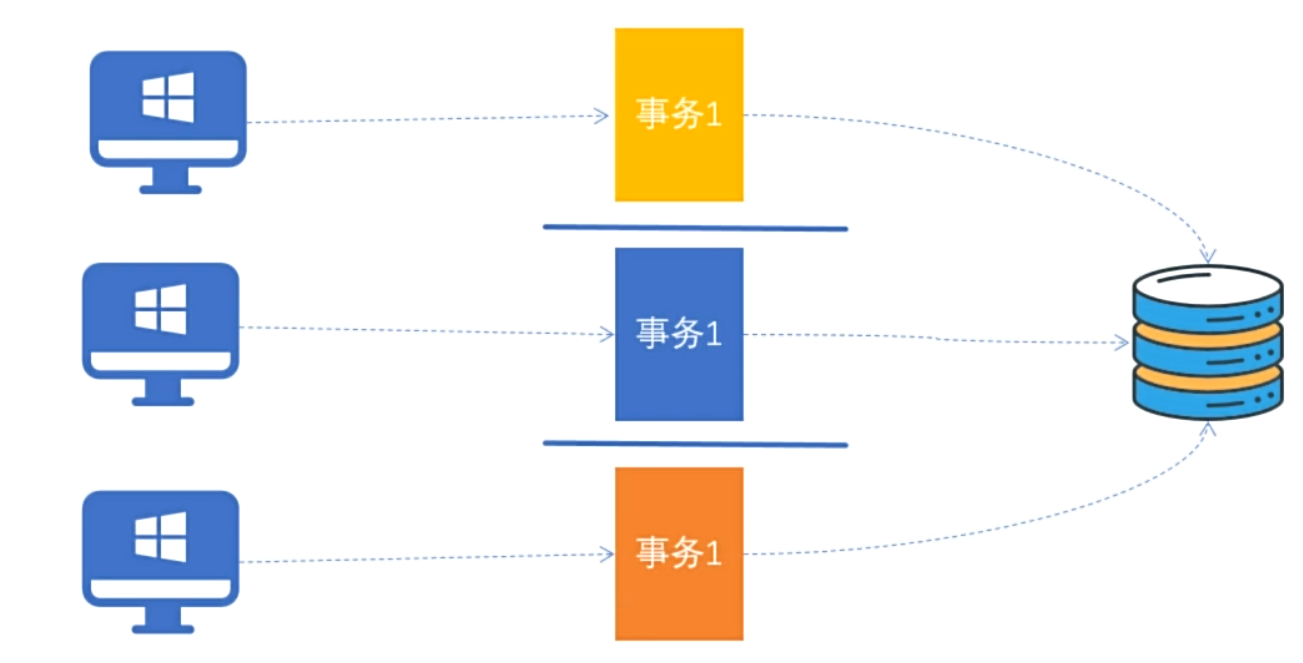
-
- 隔离级别
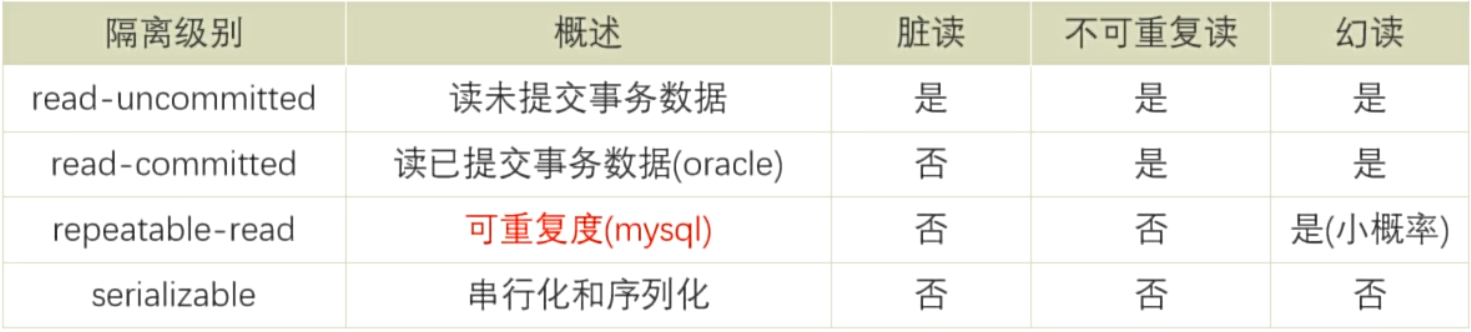
脏读:一个事务读取了另一个事务未提交的数据;
不可重复读:一个事务读取了另一个事务提交的修改数据;
幻读:一个事务读取了另一个事务提交的新增、删除的记录情况,记录数不一样,像是出现幻觉
# 修改隔离级别
set transaction_isolation = '隔离等级';
# 查看隔离级别
select @@transaction_isolation;7.2 用户权限控制
- 基本权限类型
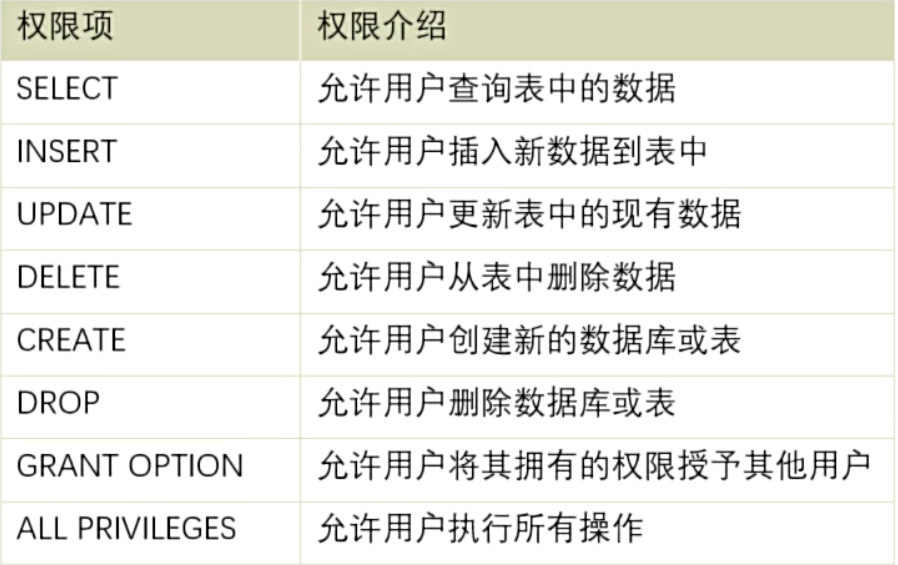
- 创建用户
CREATE USER 'username'@'localhost' IDENTIFIED BY 'password';
# localhost为用户可以连接到Mysql服务器的本地主机 使用%可以表示允许任意主机连接- 赋予权限
# 赋予全部权限
GRANT ALL PRIVILEGENS ON 数据库名.表名 TO 'username'@'localhost'
# database_name:* 表示所有库权限
# table_name:* 代表所有表
# 指定库和权限
grant 权限,权限,权限 on 数据库名.表名(* 任何库和表) to 'username'@'localhost'- 回收权限
revoke 权限,权限,权限 on 数据库名.表名 from '账号'@'主机地址'- 删除用户
drop user '用户名'- 查看用户和权限
select user,host from mysql.user;
show grants fro '账号'@'主机地址'7.3 数据库备份以及还原
- 全量备份
# 备份单库和单表
mysqldump -u username -p database_name 表名 > 文件名.sql
# 备份单库和多表
mysqldump -u username -p database_name 表名1,表名2,... > 文件名.sql
# 备份单库的所有表
mysqldump -uroot -p密码 数据库名 > 文件名.sql- 全量恢复
mysql -u username -p database_name < 文件名.sql
# 需要提取准备好数据库- 局部备份和恢复
Binlog记录数据库所有的增删改查的操作,同时也包括操作的执行时间。我们可以通过利用日志文件实现:误删数据恢复、增量复制、主从同步。
开启Binlog配置(默认开启)
Mysql配置文件目录:C:\ProgramData\MySQL\MySQL Server 8.2\my.ini
[mysqld]
# 日志文件缓存位置
datadir=C:/ProgramData/MySQL/MySQL Server 8.2/Data
# log文件名
log-bin="DESKTOP-DTNNDTT-bin"示例:
# 清空原有日志文件
RESET MASTER;
# 准备数据,插入数据 -> 000001日志文件
CREATE DATABASE test08_binlog;
USE test08_binlog;
CREATE TABLE table_01(
id INT PRIMARY KEY AUTO_INCREMENT,
`name` VARCHAR(20) NOT NULL
);
INSERT INTO table_01(`name`) VALUES('lisi'),('zhangsan');
# 重启一个新的日志文件 -> 000002日志文件
FLUSH LOGS;
# 将数据删除和插入第二个日志文件 -> 000002日志文件
DELETE FROM table_01 WHERE id = 2;
insert into table_01(`name`) VALUES('wangwu');
select * from table_01;查看日志清单:
# 查看日志清单
SHOW BINARY LOGS;
# 查看日志文件信息
SHOW BINLOG EVENTS; # 查看第一个日志的清单
SHOW BINLOG EVENTS IN '清单文件名' FROM pos LIMIT OFFSET , NUMBER; # from从哪个位置开始查询执行
SHOW BINLOG EVENTS IN 'DESKTOP-DTNNDTT-bin.000001;结果
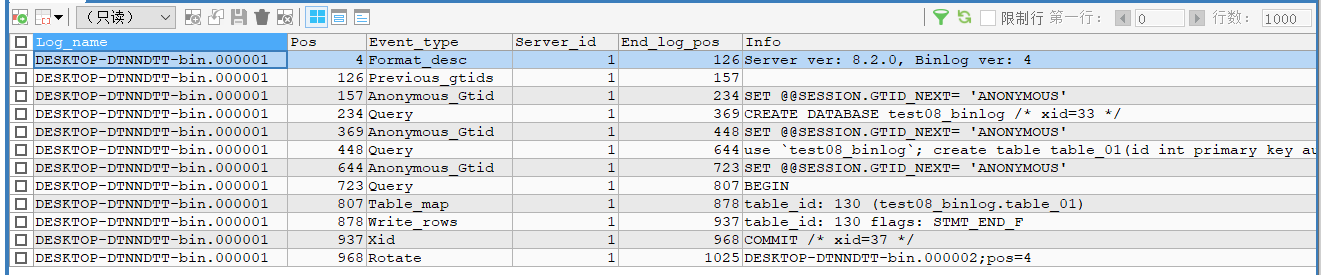
示例:
SHOW BINARY LOGS;
SHOW BINLOG EVENTS;
SHOW BINLOG EVENTS IN 'my_logbin.000002';
SHOW BINLOG EVENTS IN 'my_logbin.000002' FROM 391 LIMIT 1 , 2;查看日志文件详情:
# 这个命令需要再cmd中执行!不是mysql的链接情况
mysqlbinlog -v binlog日志文件跳过删除步骤的log找回数据,只提取删除之前和删除之后的命令
mysqlbinlog my-logbin.000001> d:/my_binlog.000001.sql # 将其他的日志完整导出
mysqlbinlog --stop-POSITION=删除命令的开始的pos my-logbin.000002 > d:/my_binlog.391.sql # 02日志删除之前
mysqlbinlog --start-POSITION=删除命令的下一个命令开始pos my-logbin.000002 > d:/my_binlog.441.sql # 02日志删除之后7.4 新特性(8+)
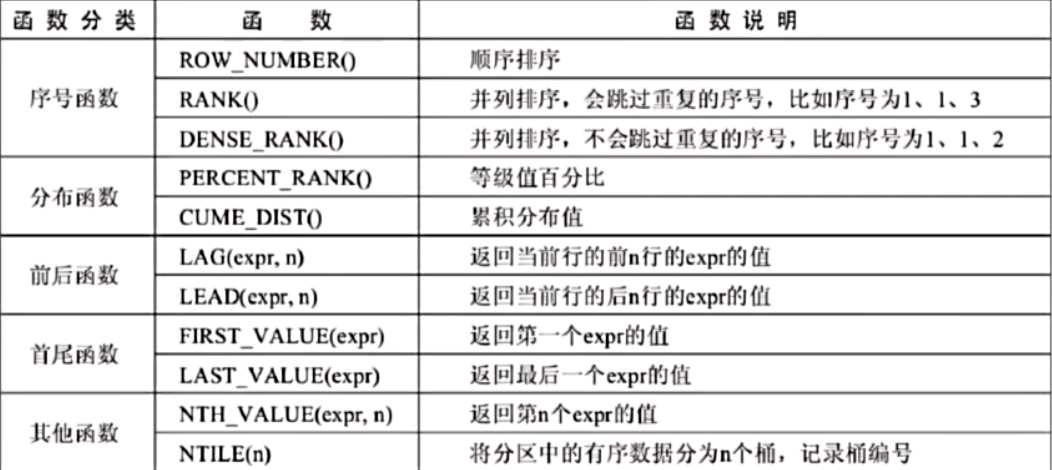
窗口函数
将多行函数分布在多行结果中
语法:
多行函数 OVER ([PARTITION BY 字段名 ORDER BY 字段名 ASC | DESC])
# 或
多行函数 OVER 窗口名... WINDOW 窗口名 AS ([PARTITION BY 字段名 ORDER BY 字段名 ASC | DESC])示例:
SELECT * ,AVG(price) OVER() FROM goods;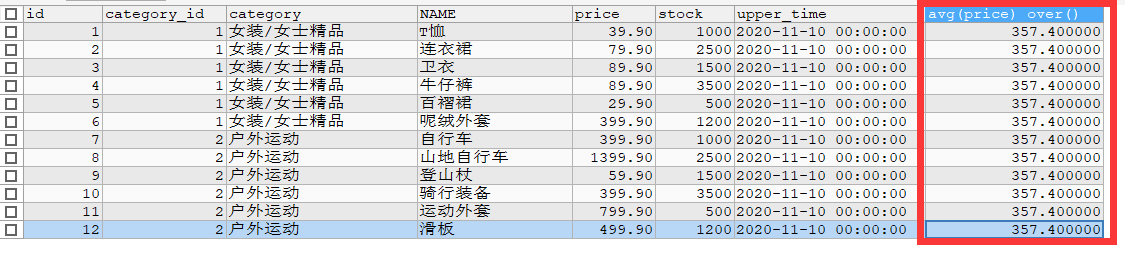
示例:
# 根据category类别分组
SELECT * ,AVG(price) OVER(PARTITION BY category) FROM goods;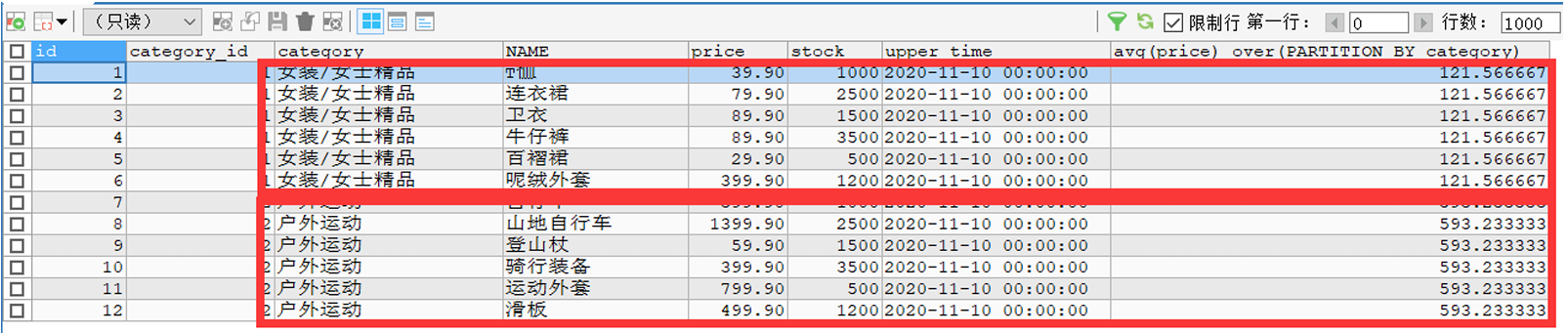
示例:
# 查询 goods 数据表中每个商品分类下价格降序排列的各个商品信息。
SELECT ROW_NUMBER() OVER(PARTITION BY category_id ORDER BY price DESC) AS row_num, id,
category_id, category, NAME, price, stock FROM goods;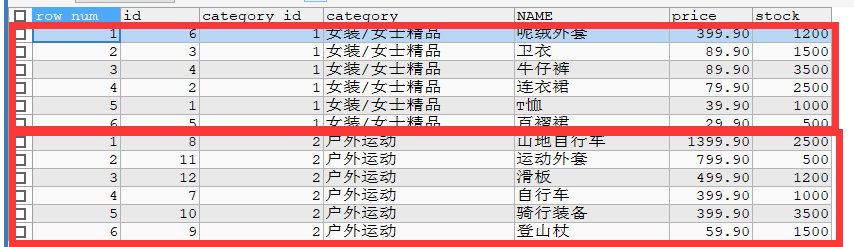

![表情[qiang] - 极核GetShell](https://get-shell.com/wp-content/themes/zibll/img/smilies/qiang.gif)


![表情[guzhang] - 极核GetShell](https://get-shell.com/wp-content/themes/zibll/img/smilies/guzhang.gif)
![表情[saorao] - 极核GetShell](https://get-shell.com/wp-content/themes/zibll/img/smilies/saorao.gif)

![表情[haixiu] - 极核GetShell](https://get-shell.com/wp-content/themes/zibll/img/smilies/haixiu.gif) 小菜鸡罢了
小菜鸡罢了